When it boils down to it, every idea in SEO can be understood as a set of measurements we use to rank one page over another. And that means that when it comes to measuring a concept like the authoritativeness of your content, there are almost certainly factors that you can analyze and tweak to improve it.
But if Google were to use a measure of content authority, what might go into it? Against what yardstick should SEOs be measuring their content’s E-A-T? In this episode of Whiteboard Friday, Russ Jones walks us through a thought experiment as to what exactly might constitute a “content authority” score and how you can begin to understand your content’s expertise like Google.
Click on the whiteboard image above to open a high-resolution version in a new tab!
Video Transcription
Hey, folks, this is Russ Jones here with another Whiteboard Friday, and today we’re going to have fun. Well, at least fun for me, because this is completely speculative. We’re going to be talking about this concept of content authority and just some ideas around ways in which we might be able to measure it.
Maybe Google uses these ways to measure it, maybe not. But at the same time, hopefully what we’ll be able to do is come up with a better concept of metrics we can use to get at content authority.
Now, we know there’s a lot of controversy around this. Google has said quite clearly that expertise, authority, and trustworthiness are very important parts of their Quality Rater Guidelines, but the information has been pretty flimsy on exactly what part of the algorithm helps determine exactly this type of content.
We do know that they aren’t using the quality rater data to train the algorithm, but they are using it to reject algorithm changes that don’t actually meet these standards.
How do we measure the authoritativeness of content?
So how can we go about measuring content authority? Ultimately, any kind of idea that we talk about in search engine optimization has to boil down in some way, shape, or form to a set of measurements that are being made and in somehow shape or form being used to rank one page over another.
Now sometimes it makes sense just to kind of feel it, like if you’re writing for humans, be a human. But authoritative content is a little bit more difficult than that. It’s a little harder to just off the top of your head know that this content is authoritative and this isn’t. In fact, the Quality Rater Guidelines are really clear in some of the examples of what would be considered really highly authoritative content, like, for example, in the News section they mention that it’s written by a Pulitzer Prize winning author.
Well, I don’t know how many of you have Pulitzer Prize winning authors on your staff or whose clients have Pulitzer Prize winning authors. So I don’t exactly see how that’s particularly helpful to individuals like ourselves who are trying to produce authoritative content from a position of not being an award-winning writer.
So today I want to just go through a whole bunch of ideas, that have been running through my head with the help of people from the community who’ve given me some ideas and bounced things off, that we might be able to use to do a better job of understanding authoritative content. All right.
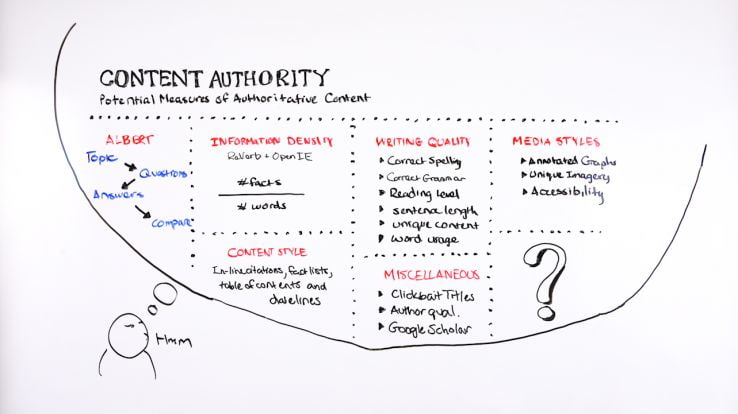
1. ALBERT
So these are what I would consider some of the potential measures of authoritative content. The first one, and this is just going to open up a whole rat’s nest I’m sure, but okay, ALBERT. We’ve talked about the use of BERT for understanding language by Google. Well, ALBERT, which stands for “a lighter BERT,” is a similar model used by Google, and it’s actually been trained in specific circumstances for the goal of answering questions.

Now that might not seem like a particularly big deal. We’ve been doing question answering for a whole long time. Featured snippets are exactly that. But ALBERT has jumped on the scene in such a dominant fashion as to have eclipsed anything we’ve really seen in this kind of NLP problem.
So if you were to go to the SQuAD dataset competition, which is Stanford’s Question Answering competition, where they’ve got these giant set of questions and giant set of documents and then they had humans go in and find the answers in the documents and say which documents don’t have answers and which do, and then all sorts of different organizations have produced models to try and automatically find the answers.
Well, this competition has just been going back and forth and back and forth for a really long time between a bunch of heavy hitters, like Google, Baidu, multiple Microsoft teams. We’re talking the smartest people in the world, the Allen Institute, all fighting back and forth.
Well, right now, ALBERT or variations thereof have the top 5 positions and 9 of the top 10 positions, and all of them perform better than humans. That is dominance. So we’ve got right here this incredible technology for answering questions.
Well, what does this have to do with content authority? Why in the world would this matter? Well, if you think about a document, any kind of piece of content that we produce, the intention is that we’re going to be answering the questions that our customers want answered. So any topic we start with, let’s say the topic we started with was data science, well, there are probably a lot of questions people want to know about that topic.
They might want to know: What is a data scientist? How much money do they make? What kind of things do you need to know to be a data scientist? Well, this is where something like ALBERT could come in and be extremely valuable for measuring the authoritativeness of the content. You see, what if one of the measures of the authoritative content is how well that content answers all of the related questions to the topic?
So you could imagine Google looking at all of the pages that rank for data science, and they know the top 10 questions that are asked about it, and then seeing which piece of content answers those 10 questions best. If they were able to do that, that would be a pretty awesome metric for determining how thorough and how significant and valuable and useful and authoritative that content is.
So I think this one, the ALBERT algorithm really has a lot of potential. But let’s move on from that. There are all sorts of other things that might have to do with content authority.
2. Information density
One that I really like is this idea of information density. So a lot of times when we’re writing content, especially when we’re not familiar with the topic, we end up writing a lot of fluff.
We kind of are just putting words in there to meet the word length that is expected by the contract, even though we know deep down that the number of words on the page really doesn’t determine whether or not it’s going to rank. So one of the ways that you can get at whether a piece of content is actually valuable or not or at least is providing important information is using natural language programs to extract information.
ReVerb + OpenIE
Well, the probably most popular NLP open source or at least openly available technology started as a project called ReVerb and now has merged into the Open IE project. But essentially, you can give it a piece of content, and it will extract out all of the factual claims made by that content.
So if I gave it a paragraph that said tennis is a sport that’s played with a racket and a ball and today I’m having a lot of fun, something of that sort, it would be able to identify the factual claim, what tennis is, that it’s a sport played with a racket and a ball.
But it would ignore the claim that I’m having a lot of fun today, because that’s not really a piece of information, a factual claim that we’re making. So the concept of information density would be the number of facts that can be extracted from a document versus the total number of words. All right.

If we had that measurement, then we could pretty easily sift through content that is just written for length versus content that is really information rich. Just imagine a Wikipedia article, how dense the information is in there relative to the type of content that most of us produce. So what are some other things?
3. Content style
Let’s talk about content style.

This would be a really easy metric. We could talk about the use of in-line citations, which Wikipedia does, in which after stating a fact they then link to the bottom of the page where it shows you the citation, just like you would do if you were writing a paper in college or a thesis, something that would be authoritative. Or the use of fact lists or tables of contents, like Wikipedia does, or using datelines accurately or AP style formatting.
These are all really simple metrics that, if you think about it, the types of sites that are more trustworthy more often use. If that’s the case, then they might be hints to Google that the content that you’re producing is authoritative. So those aren’t the only easy ones that we could look at.
4. Writing quality
There are a lot of other ones that are pretty straightforward, like dealing with writing quality.

How easy is it to make sure you are using correct spelling and correct grammar? But have you ever looked at the reading level? Has it ever occurred to you to make sure that the content that you’re writing isn’t written at a level so difficult that no one can understand it, or is written at a level so low as to be certainly not thorough and not authoritative? If your content is written at a third-grade level and the page is about some health issue, I imagine Google could use that metric pretty quickly to exclude your site.
There are also things like sentence length, which deals with readability, the uniqueness of the content, and also the word usage. This is a pretty straightforward one. Imagine that once again we’re looking at data science, and Google looks at the words you use on your page. Then maybe instead of looking at all sites that mention data science, Google only looks at edu sites or Google only looks at published papers and then compares the language usage there.
That would be a pretty easy way for Google to identify a piece of content that’s meant for consumers that is authoritative versus one that’s meant for consumers and isn’t.
5. Media styles
Another thing we can look at is media styles. This is something that is a little bit more difficult to understand how Google might actually be able to take advantage of.

But at the same time, I think that these are measurable and easy for search engine optimizers, like ourselves, to use.
Annotated graphs
One would be annotated graphs. I think we should move away from graph images and move more towards using open source graphing libraries. That way the actual factual information, the numbers can be provided to Google in the source code.
Unique imagery
Unique imagery is obviously something that we would care about. In fact, it’s actually listed in the Quality Rater Guidelines.
Accessibility
Then finally, accessibility matters. I know that accessibility doesn’t make content authoritative, but it does say something about the degree to which a person has cared about the details of the site and of the page. There’s a really famous story about, and I can’t remember what the band’s name was, but they wrote into their contracts that for every concert they needed to have a bowl of M&Ms, with all of the brown M&Ms removed, waiting for them in the room.
Now it wasn’t because they had a problem with the brown M&Ms or they really liked M&Ms or anything of that sort. It was just to make sure that they read the contract. Accessibility is kind of one of those things of where they can tell if you sweat the details or not.
6. Clickbait titles, author quality, and Google Scholar
Now finally, there are a couple of others that I think are interesting and really have to be talked about. The first is clickbait titles.
Clickbait titles
This is explicitly identified as something that Google looks at or at least the quality raters look at in order to determine that content is not authoritative. Make your titles say what they mean, not try to exaggerate to get a click.
Author quality
Another thing they say specifically is do you mention your author qualifications. Sure, you don’t have a Pulitzer Prize writer, but your writer has some sort of qualifications, at least hopefully, and those qualifications are going to be important for Google in assessing whether or not the author actually knows what they’re talking about.
Google Scholar
Another thing that I think we really ought to start looking at is Google Scholar. How much money do you think Google makes off of Google Scholar? Probably not very much. What’s the point of having a giant database of academic information when you don’t run ads on any of the pages? Well, maybe that academic information can be mined in a way so that they can judge the content that is made for consumers as to whether or not it is in line with, whether we’re talking about facts or language or authoritativeness, with what academia is saying about that same topic.

Now, course, all of these ideas are just ideas. We’ve got a giant question mark sitting out there about exactly how Google gets at content authority. That doesn’t mean we should ignore it. So hopefully these ideas will help you come up with some ideas to improve your own content, and maybe you could give me some more ideas in the comment section.
That would be great and we could talk more about how those might be measured. I’m looking forward to it. Thanks again.
Video transcription by Speechpad.com