
There are a few questions that have been confusing the SEO industry for many years. No matter how many times Google representatives try to clear the confusion, some myths persist.
One such question is the widely discussed issue of duplicate content. What is it, are you being penalized for it, and how can you avoid it?
Let’s try to clear up some of the confusion by answering some frequently-asked (or frequently-wondered) questions about duplicate content.
How can you diagnose a duplicate content penalty?
It’s funny how some of the readers of this article are rolling their eyes right now reading the first subheading. But let’s deal with this myth first thing.
There is no duplicate content penalty. None of Google’s representatives has ever confirmed the existence of such a penalty; there were no algorithmic updates called “duplicate content”; and there can never be such a penalty because in the overwhelming number of cases, duplicate content is a natural thing with no evil intent behind that. We know that, and Google knows that.
Still, lots of SEO experts keep “diagnosing” a duplicate content “penalty” when they analyze every other website.
Duplicate content is often mentioned in conjunction with updates like Panda and Fred, but it is used to identify bigger issues, i.e. thin or spammy (“spun”, auto-generated, etc.) and stolen (scraped) content.
Unless you have the latter issue, a few instances of duplicate content throughout your site cannot cause an isolated penalty.
Google keeps urging website owners to focus on high-quality expert content, which is your safest bet when it comes to avoiding having your pages flagged as a result of thin content.
You do want to handle your article republishing strategy carefully, because you don’t want to confuse Google when it comes to finding the actual source of the content. You don’t want to have your site pages filtered when you republish your article on an authoritative blog. But if it does happen, chances are, it will not reflect on how Google treats your overall site.
In short, duplicate content is a filter, not a penalty, meaning that Google has to choose one of the URLs with non-original content and filter out the rest.
So should I just stop worrying about internal duplicate content then?
In short, no. It’s like you don’t want to ignore a recurring headache: it’s not that a headache is a disease on its own, but it may be a symptom of a more serious condition, so you want to clear those out or treat them if there are any.
Duplicate content may signal some structural issues within your site, preventing Google from understanding what they should rank and what matters most on your site. And generally, while Google is getting much better at understanding how to handle different instances of the same content within your site, you still don’t want to ever confuse Google.
Internal duplicate content may signal a lack of original content on your site too, which is another problem you’ll need to deal with.
Google wants original content in their SERPs for obvious reasons: They don’t want their users to land on the same content over and over again. That’s a bad user experience. So Google will have to figure out which non-unique pages they want to show to their users and which ones to hide.
That’s where a problem can occur: The more pages on your site have original content, the more Google positions they may be able to appear at throughout different search queries.
If you want to know whether your site has any internal duplicate content issues, try using tools like SE Ranking, which crawls your website and analyzes whether there are any URLs with duplicate content Google may be confused about:

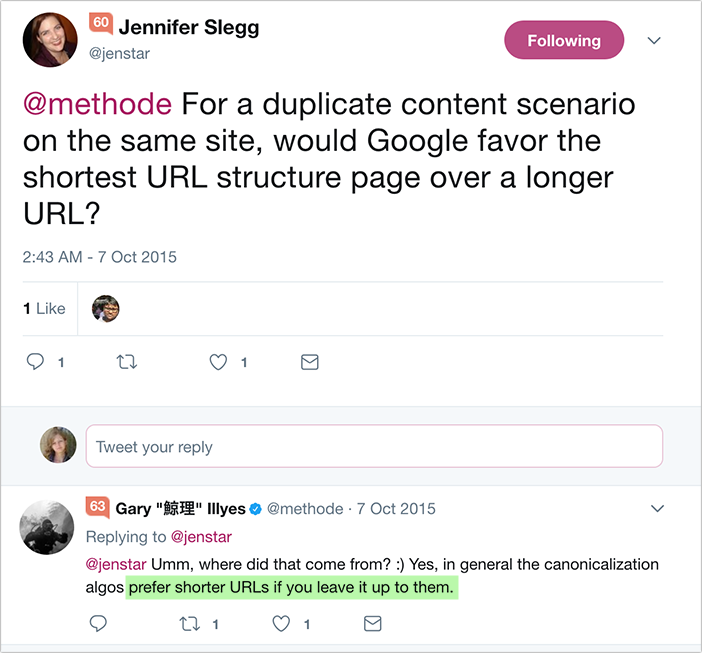
How does Google choose which non-original URLs to rank and which to filter out?
You’d think Google would want to choose the more authoritative post (based on various signals including backlinks), and they probably do.
But what they also do is choose the shorter URL when they find two more pages with identical URLs:
How about international websites? Can translated content pose a duplicate content issue?
This question was addressed by Matt Cutts back in 2011. In short, translated content doesn’t pose any duplicate content issues even if it’s translated very closely to the original.
There’s one word of warning though: Don’t publish automated translation using tools like Google Translate because Google is very good at identifying those. If you do so, you run into risk of having your content labeled as spammy.
Use real translators whom you can find using platforms like Fiverr, Upwork and Preply. You can find high-quality translators and native speakers there on a low budget.
Look for native speakers in your target language who can also understand your base language
You are also advised to use the hreflang attribute to point Google to the actual language you are using on a regional version of your website.
How about different versions of the website across different localized domains?
This can be tricky, because it’s not easy to come up with completely different content when putting up two different websites with the same products for the US and the UK, for example. But you still don’t want Google to choose.
Two workarounds:
- Focus on local traditions, jargon, history, etc. whenever possible
- Choose the country you want to focus on from within Search Console for all localized domains except .com.
There’s another old video from Matt Cutts which explains this issue and the solution:
Are there any other duplicate-content-related questions you’d like to be covered? Please comment below!