
Google Smart Bidding, the search giant’s machine learning bidding strategy, has ruffled more than a few feathers in the industry. And for good reason. It commands thousands of real-time bidding signals at its (virtual) fingertips. It can analyze 70 million signals in 100 milliseconds. For retailers casting longing glances at its results so far, things look tempting.
Especially its Target ROAS (tROAS) approach. After all, if you’re merely seeking better return on ad spend, why do you need to put together a complex search solution? Why hire expensively paid search managers, bid technologies and agency services when you can hand your budgets off to Google and let them do their magic? Well, as with all things that seem too good to be true, the right approach to working with Smart Bidding is much more complex.
With the help of a client, Crealytics (my company) went head to head with Google’s tROAS bidding. We saw a spectrum of results, but today we’ll discuss the findings from a drafts and experiments set up. (In the next article, we’ll discuss the results within a geo split environment.) For context, these were the rules:
- A control bidding approach, tested against tROAS bidding, within a drafts and experiments set up.
- We set the test environment up as an auction split, A/B comparison. However, we’ll see later how this approach was inadvertently changed, and not for the better.
- Our target was to maximize revenue and new customers at a specific ROAS.
Our first round of testing yielded results across the spectrum. Some showcased the strengths of Smart Bidding, some showed where it still has room to grow, and some were just downright odd.
The Good: Auction time bidding – more clicks and lower CPCs


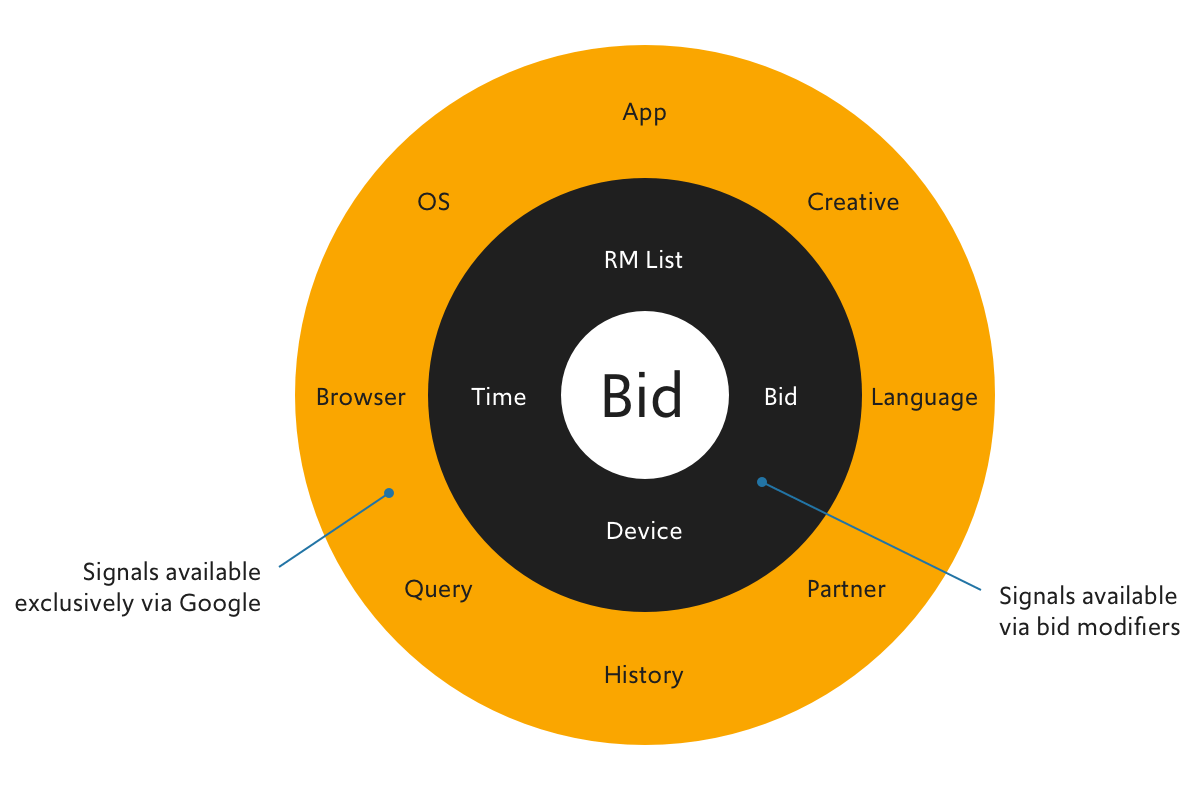
I mentioned that Smart Bidding benefits from a powerful engine. If you look under the bonnet, you’ll see the second set of signals that other bidding platforms don’t have. Matter of fact, Google freely claims that no other bidding platform will have access to a significant portion of these signals. Target ROAS draws on moment-of-query-time information for precision bids. As a result, it knows exactly where on the S-curve it needs to bid; and will never bid a cent higher than necessary to win the auction.
Such findings require some caution, however. We still aren’t sure the degree to which drafts and experiments (in conjunction with tROAS) shift volumes around internally. Pre- vs. post-comparison shows little movement; revenue only increased when spend increased. The pie shifts around…but the overall click volume and resulting revenue don’t grow much larger.


Both test markets saw marked increases in both clicks and ROAS…


…while maintaining low CPCs at the same time
The Good: More balanced bids
Google’s tROAS can also aggregate all segments at the same time. As a result, it derives the most optimal bid. Our findings bear this out: tROAS achieved more consistent performances across different segments, like devices and locations.


The Bad: No ability to optimize for advanced metrics
We always encourage clients to work towards more advanced KPIs. As an example, identifying new customers helps pave the way to judging their lifetime value (CLV). But in the current environment, Google’s Smart Bidding doesn’t seem to optimize for incremental value. New customers offer a case in point. Because the platform can’t account for this group, acquisition costs shoot upwards, and existing customers are targeted with equal value as new customers. The net result is that using new customer acquisition rate as a KPI remains a challenge under Smart Bidding.


Testing found that Smart Bidding’s algorithm overrode RLSA bid modifiers…and failed to exclude known visitors in the NC campaigns.
We also discovered that tROAS inadvertently focuses on users with high conversion propensity (i.e., strong site interaction and high recency). Audience exclusion – Google’s efforts to exclude existing customers – failed to work during the test period. Instead, it was bidding in the campaign that focused on users with more incremental conversions.
The Bad: In a race against dynamic promotions, Smart Bidding will lose (for now)
With any major account change (new product groups, new targets), tROAS regresses to its learning phase. As Fred Vallaeys mentioned previously, certain unique factors still cause machine learning to slip up. Targets will often change in respect to sales promotions, news coverage, etc. So be warned: Advertisers with highly dynamic promotional calendars should always keep an eye on proceedings (bidding manually) to avoid automated getting left behind.
The Weird: Smart Bidding tends to overwrite overlapping conversions
Drafts and experiments can use either a cookie-based or search-based split. Either drafts and experiments didn’t work with tROAS properly, or the auction eligibility changed the moment tROAS activated.
In shared customer journeys spanning both A and B campaigns (i.e., the same user was exposed to auctions won by both tROAS and our bidding approach sequentially), tROAS won the conversion 40 percent of the time. We won the conversion 21 percent of the time.
In other words, tROAS is more likely to overwrite existing cookies when a conversion is going to take place, which makes no sense given it should be a 50/50 split test.
The Weird: Decent ROAS, lower profits
Testing in a drafts and experiments setup simply can’t compare to a geo-split test environment. As noted above, campaign interference gets in the way of concise results. So, it’s no surprise our tests delivered many ambivalent results.
Top-line results promised a lot, even with a loss of efficiency in new customer acquisition.


On the flip side, our approach appears more profitable than tROAS bidding. Despite relatively small ROAS differences in Market A, we saw a wider ROI gap. Why, exactly? Because the ROI figures follow the New Customer percentage tendency as well as overall efficiency.
A lower new customer rate, particularly in the final weeks of our testing, widened this gap:


Conclusions
Ultimately, we determined that the shift in settings and the resulting change in volume settings meant a new test needed to be run. Yet there were still significant learnings to be had:
- Google drafts and experiments is a complete black box. There’s no way to unpack the selection criteria, optimization signals or decisioning systems. Retailers testing using drafts and experiments need to be prepared to lose all visibility into what makes their campaigns tick.
- If ROAS is your main KPI, you’ll likely see an upswing in performance. However, we believe there is a strong case to be made for moving towards a more advanced metric. (See here for our POV on margin and customer lifetime value.) Gaining access to bidding signals that are uniquely available to Google indeed yields benefits to the advertiser.
- Smart Bidding still has some growing to do to be useful for complex advertisers. We saw latency when reacting to dynamic promotional calendars and felt constricted when bringing in third party and attributed data sets.
In my next article, I’ll explore how Smart Bidding competes in a more transparent and open testing environment. Stay tuned…
Opinions expressed in this article are those of the guest author and not necessarily Search Engine Land. Staff authors are listed here.
About The Author



Andreas Reiffen is a thought leader in data-driven advertising. His company Crealytics works exclusively in the retail sector, and offers a holistic approach to search, shopping and paid social campaigns. Andreas is a regular speaker at industry events worldwide.