Back in September 2018, Google launched its Dataset Search tool, an engine which focuses on delivering results of hard data sources (research, reports, graphs, tables, and others) in a more efficient manner than the one which is currently offered by Google Search.
The service promises to enable easy access to the internet’s treasure trove of data. As Google’s Natasha Noy says,
“Scientists, data journalists, data geeks, or anyone else can find the data required for their work and their stories, or simply to satisfy their intellectual curiosity.”
For SEOs, it certainly has potential as a new research tool for creating our own informative, trustworthy, and useful content. But what of its prospects as a place to be visible, or as a ranking signal itself?
Google Dataset Search: As a research tool
As a writer who has been using Google to search for data since about a decade, I’d agree that finding hard statistics on search engines is not always massively straightforward.
Often, data which isn’t the most recent ranks better than newer research. This makes sense in an SEO sense, that which was published months or years prior has had a long time to earn authority and traffic. But usually I need the freshest stats, and even search results pointing to data on a page that has been published recently doesn’t necessarily mean that the data contained in that page is from that date.
Additionally, big publications (think news sites like the BBC) frequently rank better than the domain where the data was originally published. Again, this is unsurprising in the context of search engines. The BBC et al. have far more traffic, authority, inbound links, and changing content than most research websites, even .gov sites. But that doesn’t mean to say that the user looking for hard data wants to see BBC’s representation of that data.
Another key issue we find when researching hard data on Google concerns access to content. All too regularly, after a bit of browsing in the SERPs I find myself clicking through only to find that the report with the data I need is behind a paywall. How annoying.
On the surface, Google Dataset Search sets out to solve these issues.
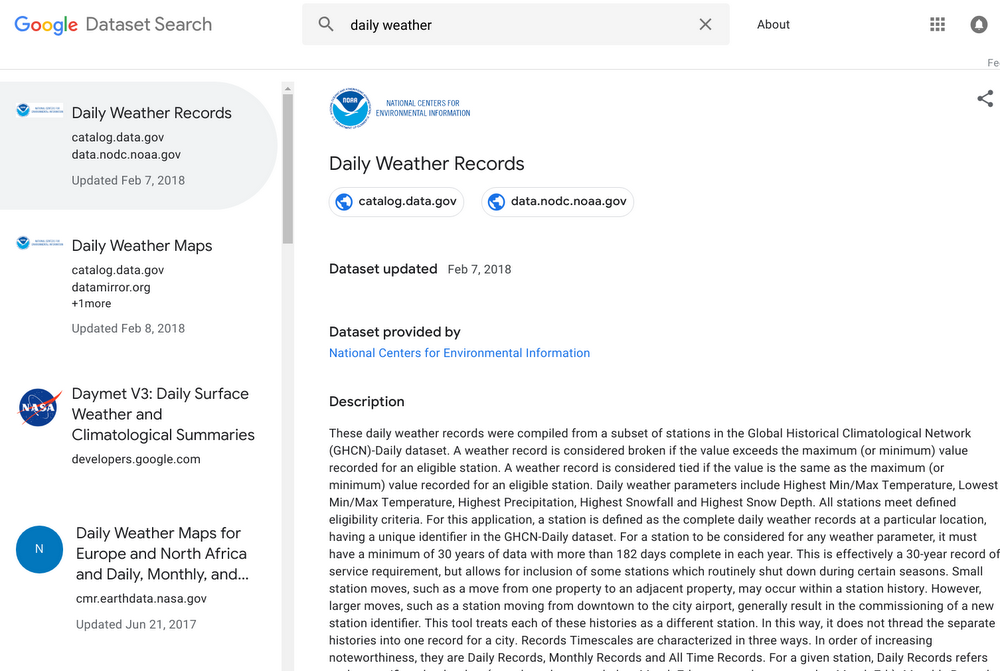
A quick search for “daily weather” (Google seems keen to use this kind of .gov data to exemplify the usefulness of the tool) shows how the service differs from a typical search at Google.com.
Results rank down the left-hand side of the page with the rest of the SERP real estate given over to more information about whichever result you have highlighted (position one is default). This description portion of the page includes:
- Key URL links to landing pages
- Key dates such as the time period the data covers, when the dataset was last updated and/or when it was first published
- Who provides the data
- The license for the data
- Its relevant geolocation
- A description of what the data is
By comparison, a search for the same keyphrase on Google in incognito mode prioritizes results for weather forecasts from Accuweather, the BBC, and the Met Office. So to have a search engine which focuses on pure, recorded data, is immediately useful.
Most results (though not all) make it clear to the user as to when the data is from and what the original source is. And by virtue of the source being included in the Dataset Search SERPs, we can be quite sure that a click through to the site will provide us access to the data we need.
Google Dataset Search: As a place to increase your visibility
As detailed on Google’s launch post for the service, Dataset Search is dependent on webmasters marking up their datasets with the Schema.org vocabulary.
Broadly speaking, Schema.org is a standardized way for developers to make information on their websites easy to crawl and understandable by search engines. SEOs might be familiar with the vocabulary if they have marked up their video content or other non-text objects on their sites. For example, whether they have sought to optimize their business for local search.
There are ample guidelines and sources to assist you with dataset markup (Schema.org homepage, Schema.org dataset markup list, Google’s reference on dataset markup, and Google’s webmaster forum are all very useful). I would argue that if you are lucky enough to produce original data, it is absolutely worth considering making it crawlable and accessible for Google.
If you are thinking about it, I’d also argue that it is important to start ranking in Google Dataset Search now. Traffic to the service might not be massive currently, but the competition to start ranking well is only going to get more difficult. The more webmasters and developers see potential in the service, the more it will be used.
Additionally, dataset markup will not only benefit your ranking in Dataset Search it will also increase your visibility for relevant data-centric queries in Google too. An important point as we see tables and stats incorporated more frequently and more intuitively in elements of the SERPs such as the Knowledge Graph.
In short:
- Getting the most out of your data is straightforward to do.
- The sooner you do, the more likely you are to have a head-start on visibility in Dataset Search before your competitors.
- And it is good best-practice for visibility in increasingly data-intuitive everyday search.
Google Dataset Search: As a ranking signal
There is a good reason to believe that being indexed in Dataset Search will be a ranking signal in its own right.
Google Scholar, which indexes scholarly literature such as journals and books has been noted by Google to provide a valuable signal about the importance and prominence of a dataset.
With that in mind, it makes sense to think a dataset that is well-optimized with clear markup and is appearing in Dataset Search would send a strong signal to Google. This would signal that the respective site is a trusted authority as a source of that type of data.
Thoughts for the future
It is early days for Google Dataset Search. But for SEO, the service is already certainly showing its potential.
As a research tool, its usefulness really depends on the community of research houses who are marking up their data for the benefit of the ecosystem. I expect the number of contributors to the service will grow quickly making for a diverse and comprehensive data tool.
I also expect that the SERPs may change considerably. They certainly work better for these kinds of queries than Google’s normal search pages. But I had some bugbears. For example, which URL am I expected to click on if a search result has more than one? Can’t all results have publication dates and the time period the data covers? Could we see images of graphs/tables in the SERPs?
But when it comes to potential as a place for visibility and a ranking signal, if you are a business that collects data and research (or you are thinking about producing this type of content), now is the time to ensure your datasets are marked up with Schema.org to beat your competitors in ranking on Google Dataset Search. This dataset best practice will also stand you in good stead as Google’s main search engine gets increasingly savvy with how it presents the world’s data.
Luke Richards is a writer for Search Engine Watch and ClickZ. You can follow Luke on Twitter at @myyada.
The post Google Dataset Search: How you can use it for SEO appeared first on Search Engine Watch.