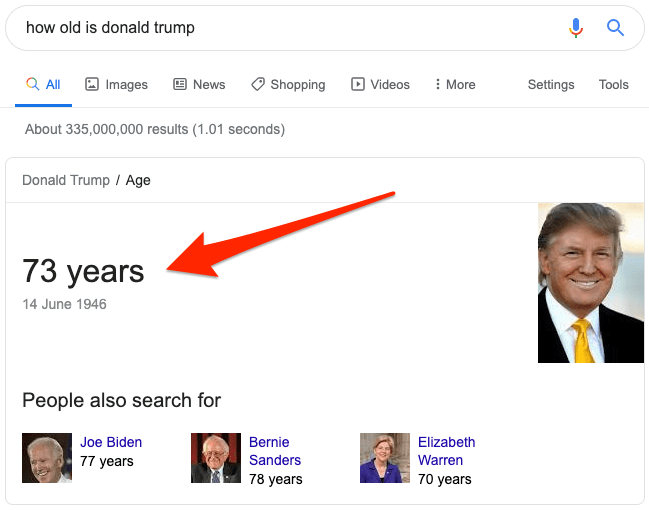
From a user’s standpoint, search engines are a modern-day miracle. You type a query into a search box, and in most cases, results from the web are sorted and ranked in milliseconds.
Popular search engines like Google have even started to answer some queries directly in the search results—which saves both time and clicks.
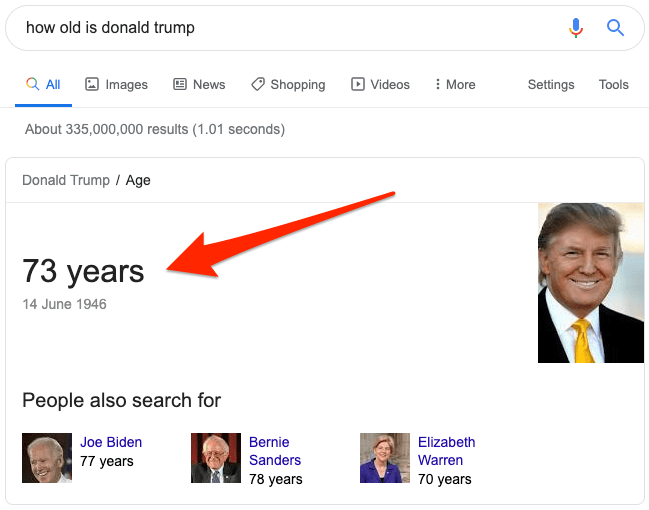
But how do search engines like Google work, and why should you care?
In this guide, you’ll learn:
What is a search engine?
A search engine consists of two main things: a database of information, and algorithms that compute which results to return and rank for a given query.
In the case of web search engines like Google, the database consists of trillions of web pages, and the algorithms look at hundreds of factors to deliver the most relevant results.
How do search engines work?
Search engines work by taking a list of known URLs, which then go to the scheduler. The scheduler decides when to crawl each URL. Crawled pages then go to the parser where vital information is extracted and indexed. Parsed links go to the scheduler, which prioritizes their crawling and re-crawling.
When you search for something, search engines return matching pages, and algorithms rank them by relevance.
Here’s a diagram from Google showing this process:
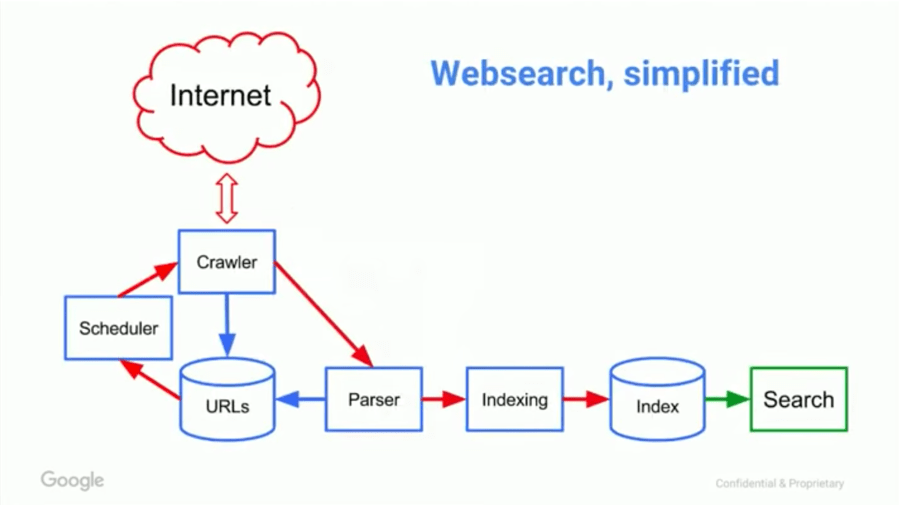
A simple diagram showing how search engines work by Google [source].
We’ll cover ranking algorithms shortly. First, let’s drill deeper into the mechanisms used to build and maintain a web index to make sure we understand how they work. These are scheduling, crawling, parsing, and indexing.
Sidenote.
This process only applies to web search engines like Google, Bing, and DuckDuckGo. There are other types of search engines like Amazon, YouTube, and Wikipedia that only show results from their website.
Scheduling
The scheduler assesses the relative importance of new and known URLs. It then decides when to crawl new URLs and how often to re-crawl known URLs.
Crawling
The crawler is a computer program that downloads web pages. Search engines discover new content by regularly re-crawling known pages where new links often get added over time.
For example, every time we publish a new blog post, it gets pushed to the top of our blog homepage, where there’s a link.
When a search engine like Google re-crawls that page, it downloads the content of the page with the recently-added links.
The crawler then passes the downloaded web page to the parser.
Sidenote.
Crawling doesn’t involve “following” links from page to page, as many people believe.
Parsing
The parser extracts links from the page, along with other key information. It then sends extracted URLs to the scheduler and extracted data for indexing.
Indexing
Indexing is where parsed information from crawled pages gets added to a database called a search index.
Think of this as a digital library of information about trillions of web pages.
What is a search engine algorithm?
Discovering and indexing content is merely the first part of the puzzle. Search engines also need a way to rank matching results when a user performs a search. This is the job of search engine algorithms.
Each search engine has unique algorithms for ranking web pages. But as Google is by far the most widely used search engine (at least in the western world), that’s the one we’re going to focus on throughout the remainder of this guide.
How does Google work?
Google works in much the same way as described above. It crawls the web and indexes the content it finds. Then, when you search for something, it finds matching results and algorithmically ranks them by relevance in a fraction of a second.
Google works so well as a search engine because of three things:
First, they crawl and re-crawl the web at a grander scale than anyone else. This has allowed them to build and maintain the largest and freshest index on the planet.
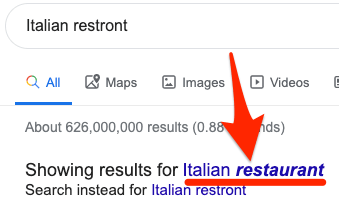
Second, they’ve invested heavily in language models that allow them to understand the true meaning behind even the most obscure or incorrect queries.
For example, they understand that if you search for “Italian restront,” you meant “Italian restaurant.”
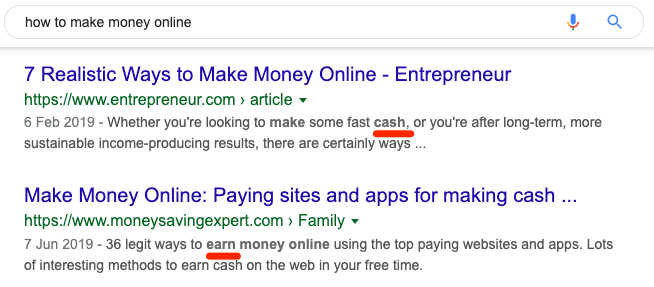
Beyond that, they also understand synonyms.
This is why when you search for “how to make money online,” you see bolded synonyms like “earn” and “cash” in the results.
They’re so good at this that some search results don’t even mention the exact search query.
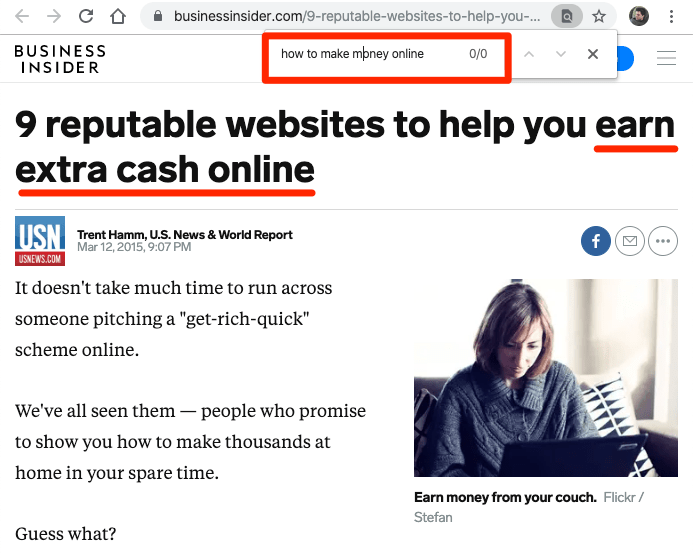
Here, Google understands “earn extra cash online” means the same as “make money online” and that it’s a relevant result for the search query.
Third, and most crucially, their ranking algorithms arguably return the most relevant results of all search engines.
How Google’s search algorithms work
Google looks at hundreds of factors to find and rank relevant content. Nobody knows what all of these are, but we do know about the key ones.
Let’s discuss a few of them.
Topical relevance
Google states that when a web page contains the same keywords as the search query, especially in prominent positions like headings, then that’s a sign of relevance.
But this idea isn’t foolproof, which is why Google also looks for the presence of other relevant words on the page.
Here’s how Google explains it:
Just think: when you search for ‘dogs’, you probably don’t want a page with the word ‘dogs’ on it hundreds of times. With that in mind, algorithms assess if a page contains other relevant content beyond the keyword ‘dogs’ – such as pictures of dogs, videos or even a list of breeds.
To give another example, let’s say you have an article about “how to get a driver’s license.” It should probably have subsections about licensing for cars, motorcycles, and buses, and mention words and phrases like road, driving, license, exam, safety, and full-privilege license.
The presence of related words and phrases like these likely helps to increase Google’s confidence that your page is about what it says it is.
To give another example, imagine that you want to create a list of the best actors.
Look at any of the results on the first page, and you’ll notice something interesting: they almost all mention people like Robert De Niro, Jack Nicholson, and Meryl Streep.
Mentioning these people, or entities, on your page may help to increase Google’s confidence that the page is a relevant result for queries like “best actors.”
Search intent
Google knows that people perform searches for a reason, and that understanding this reason helps them return better search results and creates more satisfied users.
In other words, they work hard to rank content that users expect to see.
That’s why all of the top results for “iPhone X unboxing” are videos…
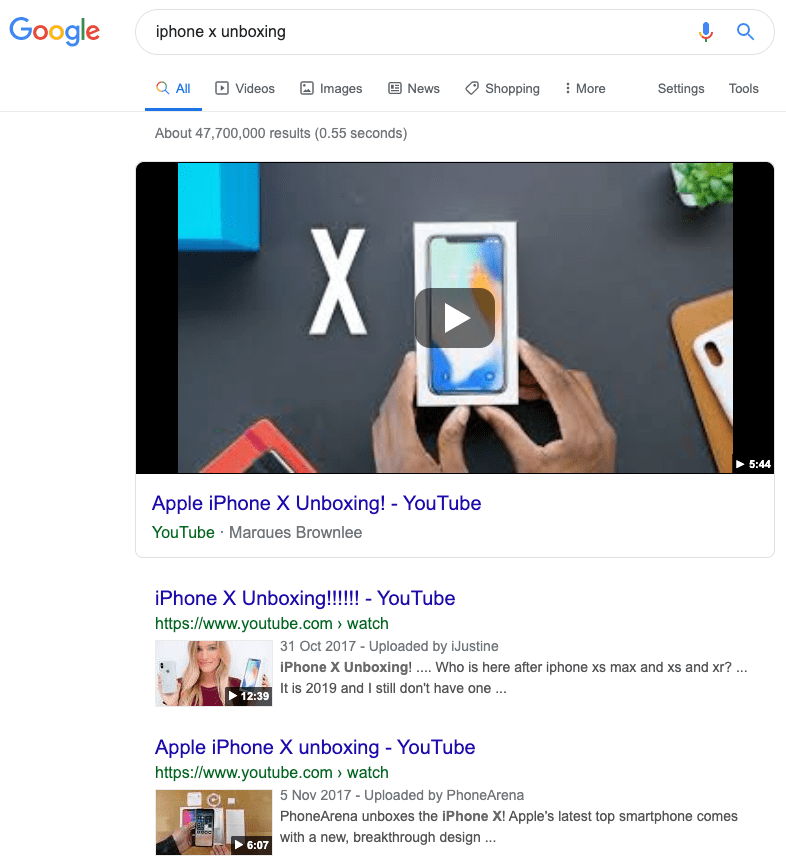
… whereas results for “iPhone X box” are images and product listings:
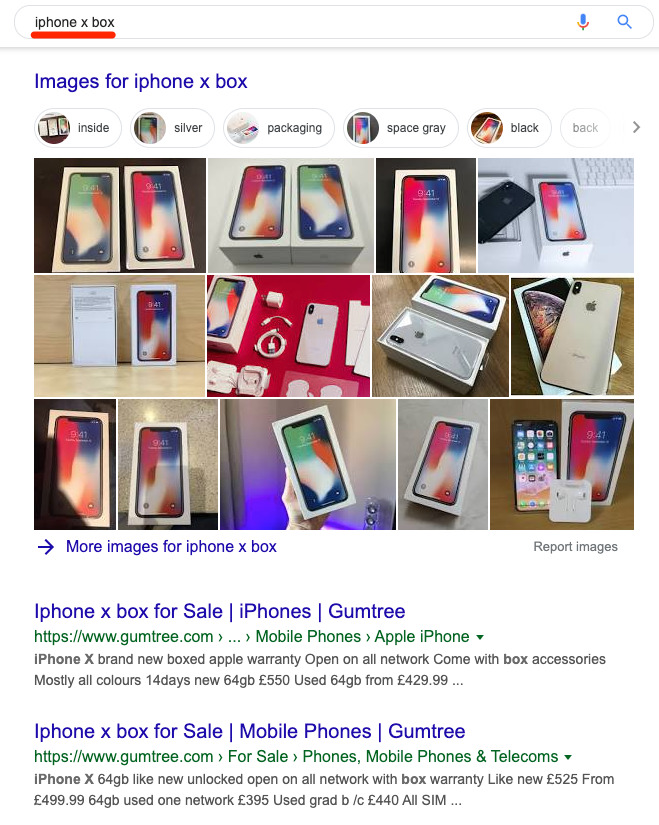
Google understands that despite the use of similar language, the intent behind these searches is entirely different. They work hard to deliver results matching the content style, content type, content format, and content angle that users want to see.
These are known as the 4 C’s of search intent.
Content style
Content style can be divided into three buckets: videos, images, and text-based content.
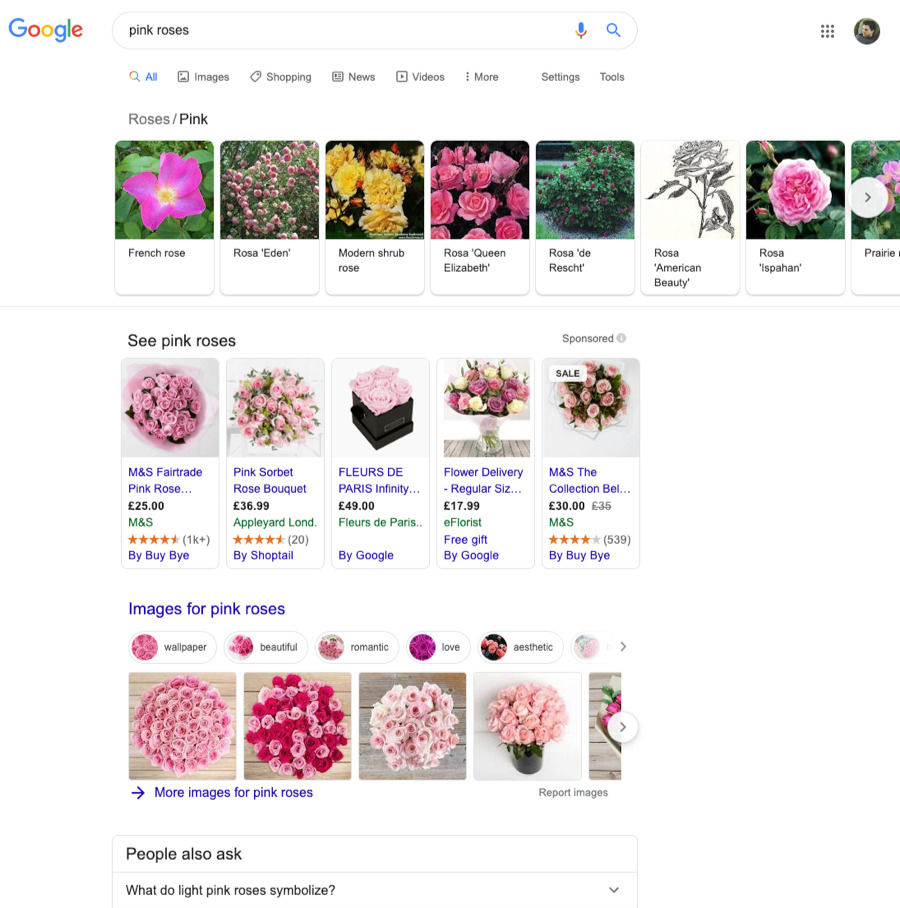
For most queries, the dominant and most desirable style of content in the results is quite clear cut. For others, like “pink roses,” Google understands that intent is mixed and shows multiple styles of content.
Content type
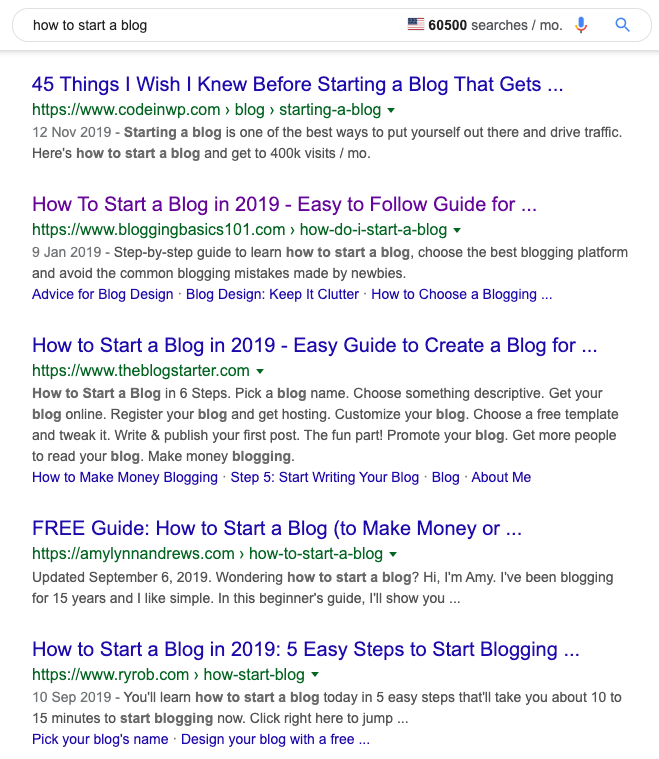
Content type usually falls into one of four buckets: blog posts, product, category, and landing pages.
For example, all of the results for “how to start a blog” are blog posts.
Content format
Content format applies mostly to blog posts, videos, and landing pages. For blog posts, common styles are “how to’s,” list posts, tutorials, opinion pieces, and news articles.
All of the results for “blogging tips” are list posts.

For landing pages, the format might be an interactive calculator or tool.
Content angle
Content angle refers to the main selling point of the content. For most queries, there’s a dominant angle in the search results.
For example, most of the top-ranking results for “blogging tips” are focussed around beginners.
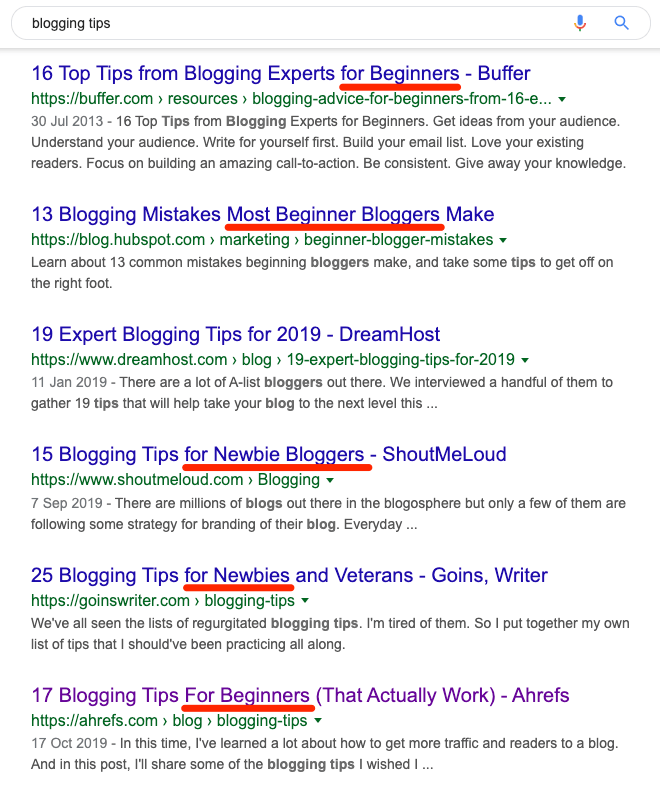
Google doesn’t rank lists of advanced tips here because that’s not what searchers want to see.
Recommended reading: Search Intent: The Overlooked ‘Ranking Factor’ You Should Be Optimizing for in 2019
Freshness
Google knows that the freshness of results matters more for some searches than others.
For example, a query like “what’s new on Netflix” requires super-fresh results because searchers want to know about movies and TV shows that were recently added to the video-streaming platform. As a result, Google prioritizes search results that were published or updated super recently.
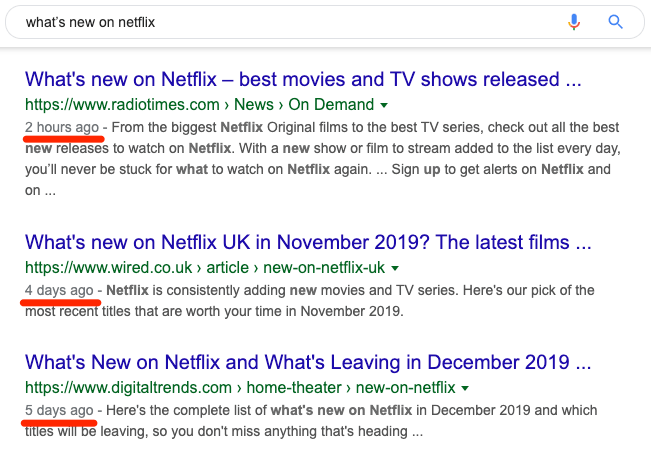
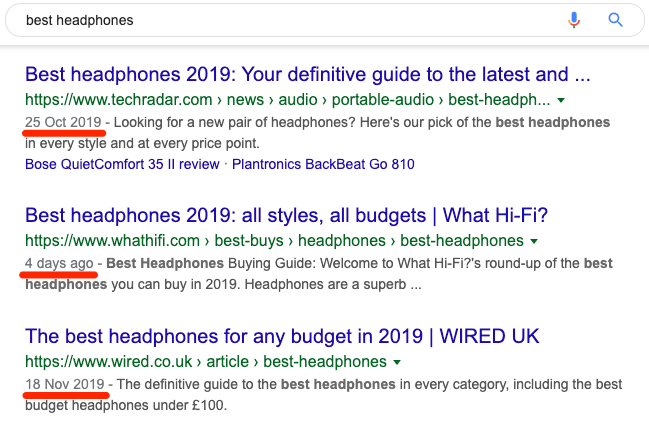
For queries like “best headphones,” freshness still matters—but not quite as much. In other words, a list from 2015 is unlikely to be of much use because headphone technology moves fast. It just doesn’t move so fast that a post published last month is no longer useful.
Google knows this and shows results that were updated or published in the past few months.
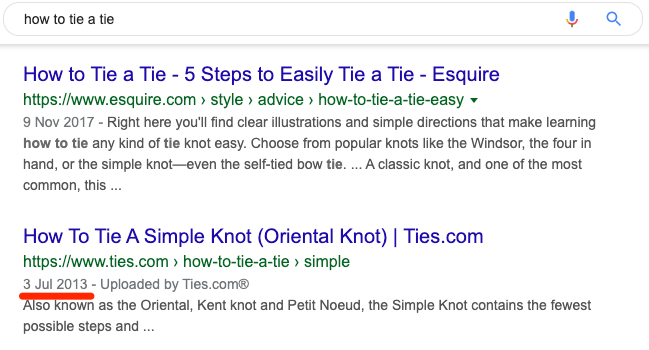
There are also queries where the freshness of results is mostly irrelevant, such as “how to tie a tie.” Nothing has changed about this process in decades (or has it?), so it doesn’t matter if the search results are from yesterday or 1998. Google knows this and has no qualms about ranking a result from 2013 in position #2.
Content quality
Google wants to rank high-quality content above low-quality content. The problem is that content quality is objectively tricky to nail, so Google looks at something called E‑A-T in an attempt to do so.
What does E‑A-T stand for?
- Expertise;
- Authoritativeness; and:
- Trust
Here’s how E‑A-T works in a nutshell:
Let’s say that you search for “how to write a song.” Given a choice, you’d almost certainly prefer to read something by Beyonce than me. Why? Because Beyonce is a songwriting expert and authority figure who you trust to give useful advice on the topic.
Now, while E‑A-T is important for all queries, it’s crucial for what Google likes to call YMYL or Your Money or Your Life searches.
Google says YMYL queries are those that could potentially impact a person’s future happiness, health, financial stability, or safety.
For example, take a query like “safe dosage of ibuprofen?”
In this case, returning results that fail to demonstrate E‑A-T could have life-threatening implications. If a page is inaccurate, then it shouldn’t appear in search results—regardless of how “topically relevant” it happens to be.
That said, the content itself isn’t the only thing that influences E‑A-T. Things like backlinks pointing to the page also matter.
Think of backlinks as votes from other websites. When someone links to a page, they’re vouching for that piece of content and recommending it to their readers.
This is probably why most large-scale studies show a clear correlation between backlinks and rankings, including our study of 920 million pages:
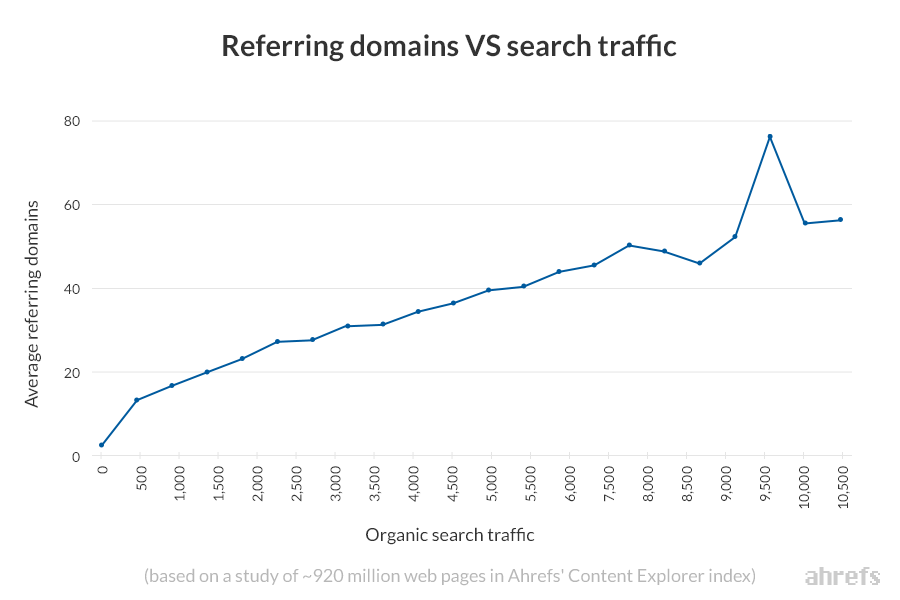
Results from our study of ~920 million web pages.
That said, it’s important to note that not all backlinks are created equal. The relevance and authority of the linking website and web page are also important.
For example, say you have an article about starting a business. Google will give more weight to a backlink from the Small Business Administration’s guide to funding your business than a similar one from a post on your friend’s blogspot site about what they did last weekend.
Usability
Google wants to rank web pages that make their users happy, and that goes beyond returning relevant results. The content also needs to be accessible and easy to consume.
There are a couple of confirmed ranking factors that help with that.
Page speed
Nobody likes waiting for pages to load, and Google knows it. That’s why they made page speed a ranking factor for desktop searches in 2010, and subsequently for mobile searches in 2018.
Mobile-friendliness
65% of Google searches happen on mobile devices, which explains why mobile-friendliness is a ranking factor for mobile searches as of 2015.
And, since July 2019, mobile-friendliness is also a ranking factor for desktop searches thanks to Google’s switch to “mobile-first indexing.” This means that Google “predominantly uses the mobile version of the content for indexing and ranking” across all devices.
Personalization
Google states that “information such as your location, past search history and search settings all help [us] to tailor your results to what is most useful and relevant for you in that moment.”
For example, a search for “best Mexican restaurant” uses your location to return local results—even outside of the “map pack.”
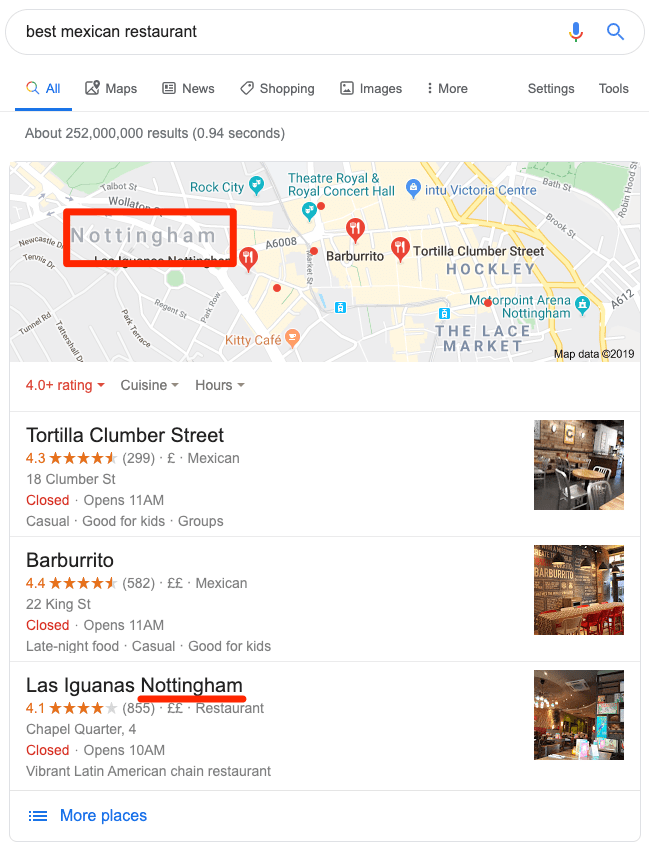
This happens because Google knows you’re not going to fly halfway around the world for lunch.
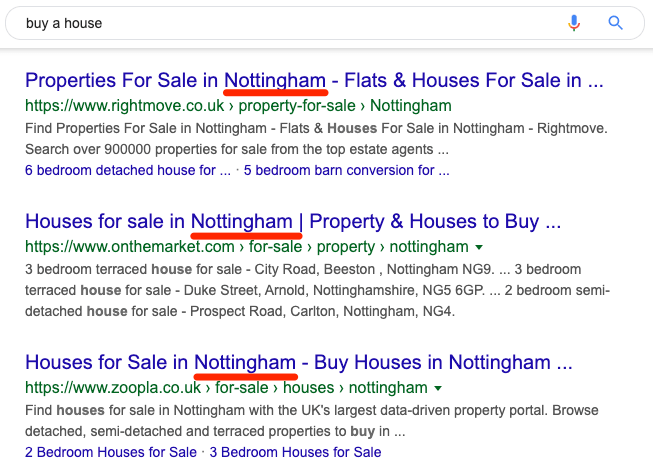
It’s a similar story for a query like “buy a house.” Google returns pages with local listings as opposed to national ones because chances are you’re not looking to relocate to a different country.
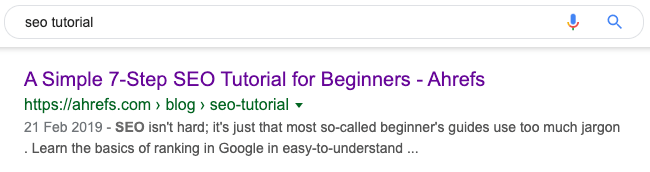
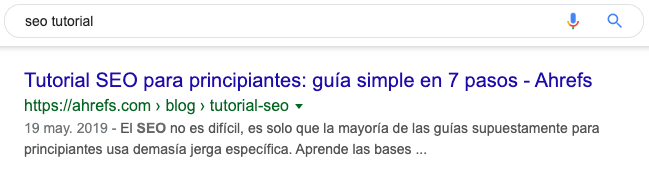
Language is another important factor. After all, there’s no point showing English results to Spanish users. That’s why Google ranks the English version of our SEO tutorial in countries where the dominant language is English and the Spanish version in countries where the dominant language is Spanish.
Recommended reading: Hreflang: The Easy Guide for Beginners
Why should you care how Google works?
Knowing how Google finds and ranks content improves your ability to create pages that show up in the search results. If you go in blind without any understanding of what Google values, or even how they discover content, your chances of ranking are slim to none.
Making efforts to rank higher in Google is known as Search Engine Optimization (SEO).
SEO is a priority for lots of businesses because:
- Traffic is “free” from SEO efforts;
- Traffic is consistent month after month (as long as you can maintain rankings);
- It provides the ability to reach a big audience in some cases.
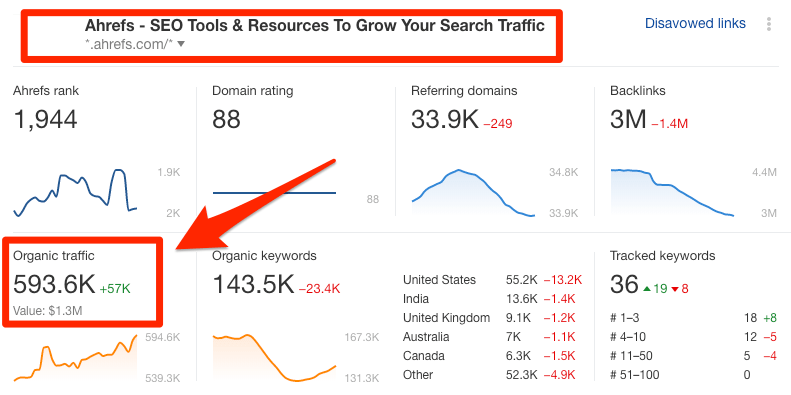
Here at Ahrefs, we’ve been investing heavily in SEO for a few years, and we now get almost 600,000 visits from Google every month.
Looking to learn more about SEO? Read our 7‑step SEO tutorial or watch the video below.
Final thoughts
Many people chase search engine algorithms, continually looking for loopholes that allow them to rank with relative ease. While this sometimes works for a short while, it rarely works long term and can even result in a dreaded Google penalty.
The key to ranking long-term is to focus on creating content that delivers the best information for the target keyword, and the best user experience.
In other words, create content primarily for users, not search engines.
Got questions? Let me know in the comments or on Twitter.