When you incorporate machine learning techniques to speed up SEO recovery, the results can be amazing.
This is the third and last installment from our series on using Python to speed SEO traffic recovery. In part one, I explained how our unique approach, that we call “winners vs losers” helps us quickly narrow down the pages losing traffic to find the main reason for the drop. In part two, we improved on our initial approach to manually group pages using regular expressions, which is very useful when you have sites with thousands or millions of pages, which is typically the case with ecommerce sites. In part three, we will learn something really exciting. We will learn to automatically group pages using machine learning.
As mentioned before, you can find the code used in part one, two and three in this Google Colab notebook.
Let’s get started.
URL matching vs content matching
When we grouped pages manually in part two, we benefited from the fact the URLs groups had clear patterns (collections, products, and the others) but it is often the case where there are no patterns in the URL. For example, Yahoo Stores’ sites use a flat URL structure with no directory paths. Our manual approach wouldn’t work in this case.
Fortunately, it is possible to group pages by their contents because most page templates have different content structures. They serve different user needs, so that needs to be the case.
How can we organize pages by their content? We can use DOM element selectors for this. We will specifically use XPaths.
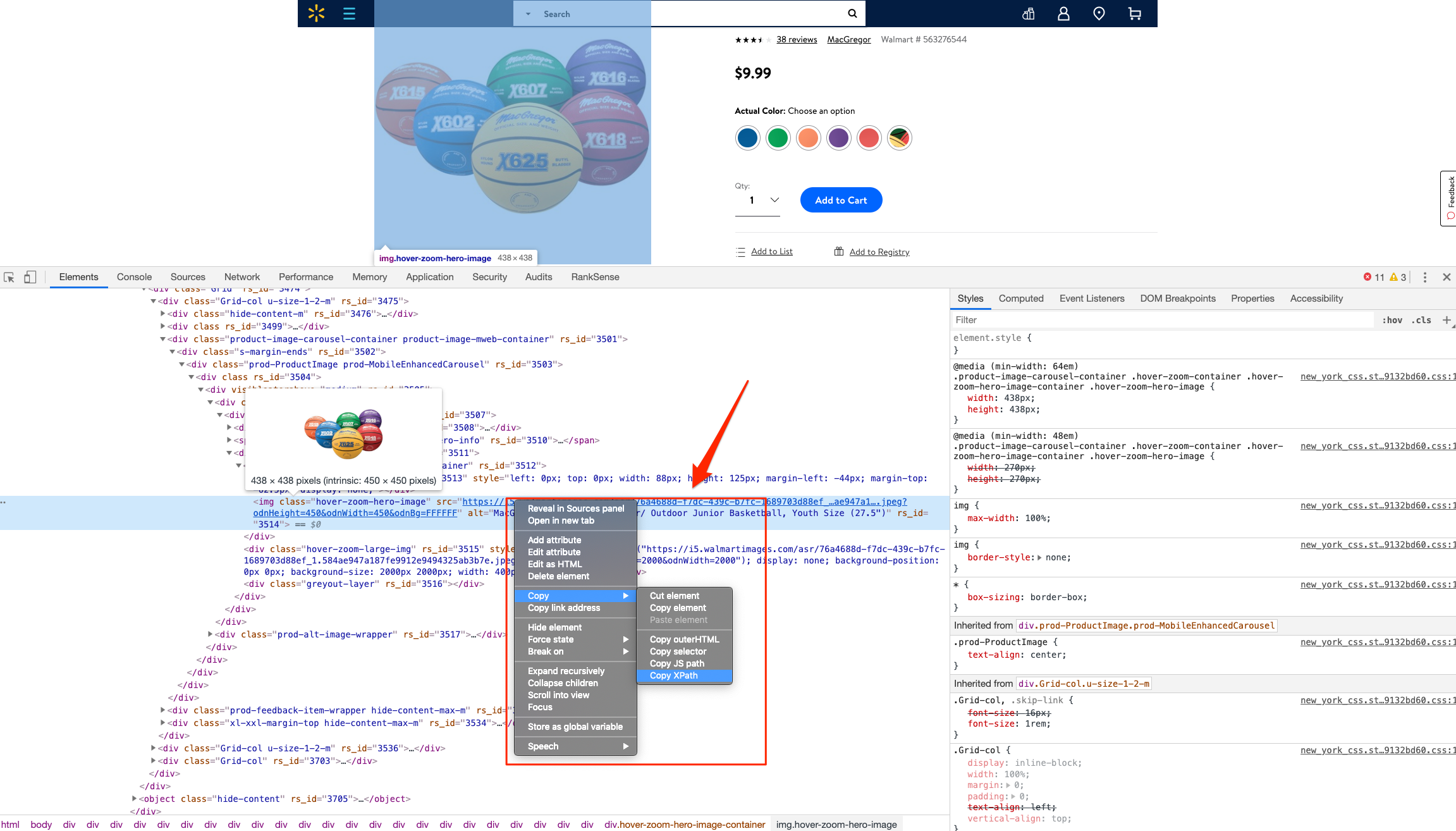
For example, I can use the presence of a big product image to know the page is a product detail page. I can grab the product image address in the document (its XPath) by right-clicking on it in Chrome and choosing “Inspect,” then right-clicking to copy the XPath.
We can identify other page groups by finding page elements that are unique to them. However, note that while this would allow us to group Yahoo Store-type sites, it would still be a manual process to create the groups.
A scientist’s bottom-up approach
In order to group pages automatically, we need to use a statistical approach. In other words, we need to find patterns in the data that we can use to cluster similar pages together because they share similar statistics. This is a perfect problem for machine learning algorithms.
BloomReach, a digital experience platform vendor, shared their machine learning solution to this problem. To summarize it, they first manually selected cleaned features from the HTML tags like class IDs, CSS style sheet names, and the others. Then, they automatically grouped pages based on the presence and variability of these features. In their tests, they achieved around 90% accuracy, which is pretty good.
When you give problems like this to scientists and engineers with no domain expertise, they will generally come up with complicated, bottom-up solutions. The scientist will say, “Here is the data I have, let me try different computer science ideas I know until I find a good solution.”
One of the reasons I advocate practitioners learn programming is that you can start solving problems using your domain expertise and find shortcuts like the one I will share next.
Hamlet’s observation and a simpler solution
For most ecommerce sites, most page templates include images (and input elements), and those generally change in quantity and size.

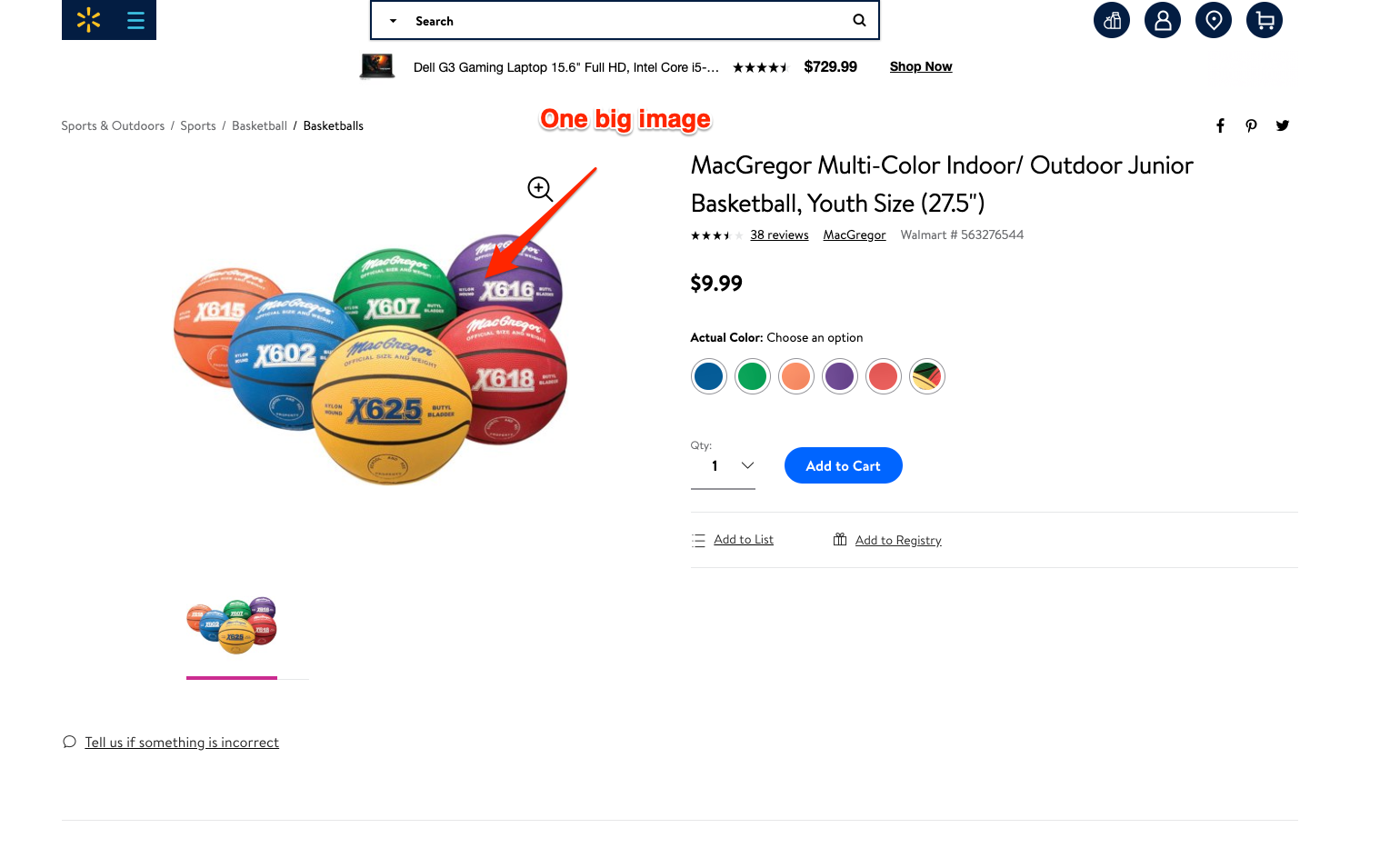
I decided to test the quantity and size of images, and the number of input elements as my features set. We were able to achieve 97.5% accuracy in our tests. This is a much simpler and effective approach for this specific problem. All of this is possible because I didn’t start with the data I could access, but with a simpler domain-level observation.
I am not trying to say my approach is superior, as they have tested theirs in millions of pages and I’ve only tested this on a few thousand. My point is that as a practitioner you should learn this stuff so you can contribute your own expertise and creativity.
Now let’s get to the fun part and get to code some machine learning code in Python!
Collecting training data
We need training data to build a model. This training data needs to come pre-labeled with “correct” answers so that the model can learn from the correct answers and make its own predictions on unseen data.
In our case, as discussed above, we’ll use our intuition that most product pages have one or more large images on the page, and most category type pages have many smaller images on the page.
What’s more, product pages typically have more form elements than category pages (for filling in quantity, color, and more).
Unfortunately, crawling a web page for this data requires knowledge of web browser automation, and image manipulation, which are outside the scope of this post. Feel free to study this GitHub gist we put together to learn more.
Here we load the raw data already collected.
Feature engineering
Each row of the form_counts data frame above corresponds to a single URL and provides a count of both form elements, and input elements contained on that page.
Meanwhile, in the img_counts data frame, each row corresponds to a single image from a particular page. Each image has an associated file size, height, and width. Pages are more than likely to have multiple images on each page, and so there are many rows corresponding to each URL.
It is often the case that HTML documents don’t include explicit image dimensions. We are using a little trick to compensate for this. We are capturing the size of the image files, which would be proportional to the multiplication of the width and the length of the images.
We want our image counts and image file sizes to be treated as categorical features, not numerical ones. When a numerical feature, say new visitors, increases it generally implies improvement, but we don’t want bigger images to imply improvement. A common technique to do this is called one-hot encoding.
Most site pages can have an arbitrary number of images. We are going to further process our dataset by bucketing images into 50 groups. This technique is called “binning”.
Here is what our processed data set looks like.

Adding ground truth labels
As we already have correct labels from our manual regex approach, we can use them to create the correct labels to feed the model.
We also need to split our dataset randomly into a training set and a test set. This allows us to train the machine learning model on one set of data, and test it on another set that it’s never seen before. We do this to prevent our model from simply “memorizing” the training data and doing terribly on new, unseen data. You can check it out at the link given below:
Model training and grid search
Finally, the good stuff!
All the steps above, the data collection and preparation, are generally the hardest part to code. The machine learning code is generally quite simple.
We’re using the well-known Scikitlearn python library to train a number of popular models using a bunch of standard hyperparameters (settings for fine-tuning a model). Scikitlearn will run through all of them to find the best one, we simply need to feed in the X variables (our feature engineering parameters above) and the Y variables (the correct labels) to each model, and perform the .fit() function and voila!
Evaluating performance

After running the grid search, we find our winning model to be the Linear SVM (0.974) and Logistic regression (0.968) coming at a close second. Even with such high accuracy, a machine learning model will make mistakes. If it doesn’t make any mistakes, then there is definitely something wrong with the code.
In order to understand where the model performs best and worst, we will use another useful machine learning tool, the confusion matrix.
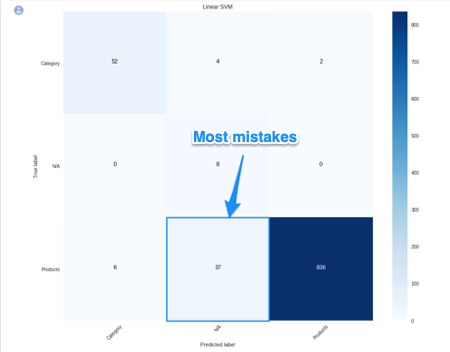
When looking at a confusion matrix, focus on the diagonal squares. The counts there are correct predictions and the counts outside are failures. In the confusion matrix above we can quickly see that the model does really well-labeling products, but terribly labeling pages that are not product or categories. Intuitively, we can assume that such pages would not have consistent image usage.
Here is the code to put together the confusion matrix:
Finally, here is the code to plot the model evaluation:
Resources to learn more
You might be thinking that this is a lot of work to just tell page groups, and you are right!
Mirko Obkircher commented in my article for part two that there is a much simpler approach, which is to have your client set up a Google Analytics data layer with the page group type. Very smart recommendation, Mirko!
I am using this example for illustration purposes. What if the issue requires a deeper exploratory investigation? If you already started the analysis using Python, your creativity and knowledge are the only limits.
If you want to jump onto the machine learning bandwagon, here are some resources I recommend to learn more:
- Attend a Pydata event I got motivated to learn data science after attending the event they host in New York.
- Hands-On Introduction To Scikit-learn (sklearn)
- Scikit Learn Cheat Sheet
- Efficiently Searching Optimal Tuning Parameters
- If you are starting from scratch and want to learn fast, I’ve heard good things about Data Camp.
Got any tips or queries? Share it in the comments.
Hamlet Batista is the CEO and founder of RankSense, an agile SEO platform for online retailers and manufacturers. He can be found on Twitter @hamletbatista.
The post Using Python to recover SEO site traffic (Part three) appeared first on Search Engine Watch.