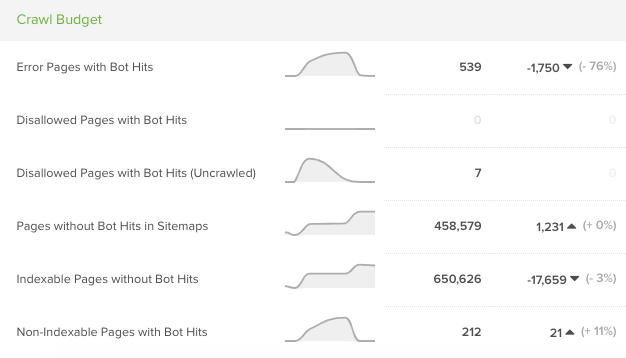
Crawl budget optimization is crucial for focusing the attention of search engine crawlers onto your website’s most important pages each time they visit.
Some of the key benefits of improving crawl budget include:
- Reduced server/bandwidth costs.
- Increased crawl rate of valuable pages.
- Increased speed of discovery of new pages.
- Increased speed of updating changed pages in the index.
Googlebot is well-equipped to be able to crawl through the majority of pages on smaller sites with each visit, so that explains why Googlers like John Mueller don’t want website owners to waste time worrying about sites that will be crawled just fine.
IMO crawl-budget is over-rated. Most sites never need to worry about this. It’s an interesting topic, and if you’re crawling the web or running a multi-billion-URL site, it’s important, but for the average site owner less so.
— 🍌 John 🍌 (@JohnMu) May 30, 2018
However, crawl budget analysis isn’t just about seeing what Googlebot is or isn’t crawling.
There is a lot of value to be gained from analyzing search engine bot behavior in more detail, and that’s why every SEO should incorporate it into their day-to-day work.
What Log Files Can Reveal About Search Engine Behavior
By delving into log files, you are able to see how search engines crawl, not just what they crawl.
You can piece together a valuable picture of what search engines find important and what they struggle with, by mapping out the journey of each crawler with log file data.
Here are five key ways to filter your log file data to get the most impactful insights into search engine behavior:
- Status code
- Indexability
- Internal linking
- Site category
- Organic performance
To try out the following methods yourself, you’ll need access to:
- A site’s log files (or a tool like Sunlight which monitors search engine bot activity through a tracking tag).
- A crawling tool that integrates data from tools like Google Analytics and Google Search Console.
- A good old-fashioned spreadsheet to do some filtering and pivoting.
1. Status Code
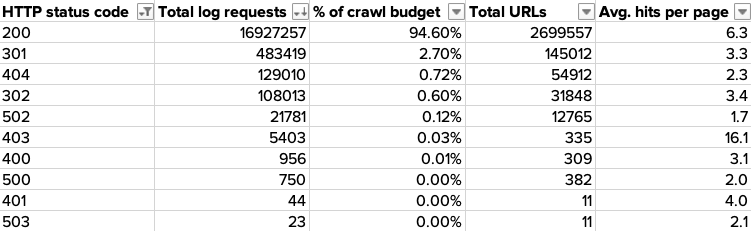
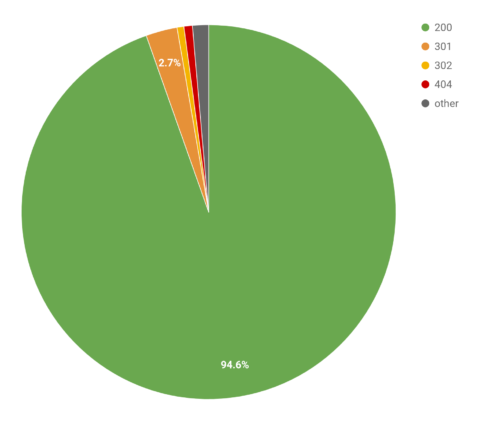
You can assess how crawl budget is being distributed across the different pages on your site through grouping your log file data by status code.
This gives you a top-level overview of how much of a search engine’s crawl budget is being spent on important 200 pages, and how much is being wasted on error pages and redirects.
Actions
Off the back of this data, here are some steps you can take to improve crawl budget across your site:
- Analyze the 200 status code URLs to identify any that don’t need to be crawled.
- Add disallow rules to your robots.txt file for non-essential pages with 200 status codes to make them inaccessible to crawlers.
- Remove internal links to 404 pages, and redirect them where necessary.
- Remove all non-200 status code pages from XML sitemaps.
- Fix redirect chains to make sure that there is only one step in each redirect being accessed by search engine crawlers and users.
2. Indexability
There are a number of different factors that impact whether a page will be indexed by search engines, such as meta noindex tags and canonical tags.
This is the kind of data that you can get from a crawling tool and combine with your log file data to analyze any disparities between pages being crawled vs indexed.
It’s important to make sure that search engine bots aren’t wasting its time crawling pages that can’t even be added to or updated in the index.
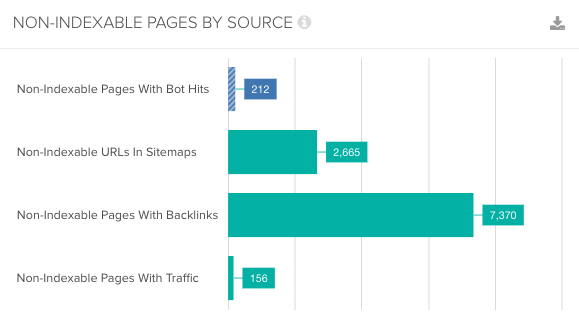
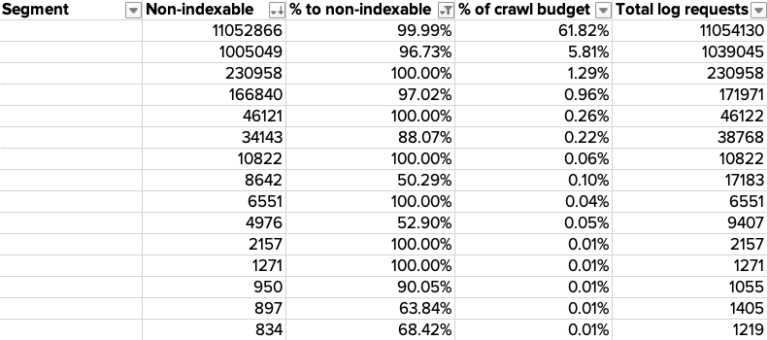
Actions
Once you’ve gathered this data, here are some steps you can take to tackle non-indexable pages and improve crawl efficiency:
- Check that non-indexable pages being crawled aren’t actually important pages that should be allowed to be indexed.
- Add disallow paths in your robots.txt file to block low quality, non-indexable pages from being crawled.
- Add relevant noindex tags and canonical tags to pages to show search engines that they are of low importance.
- Identify disallowed pages that are being crawled by search engines that are being blocked by robots.txt rules.
- Make sure that your Google Search Console parameter settings are correct and up to date.
3. Internal Linking
Internal links carry a great deal of weight in terms of influencing which pages search engines should crawl more frequently.
The more internal links a page has, the more easily discoverable it is, and the greater the chances it has of being crawled more frequently each time Google visits your site.
Overlaying bot hit data with internal linking data allows you to build a picture of how much search engines have an understanding of your website and its structure, and how easily accessible they find the different areas of your site.
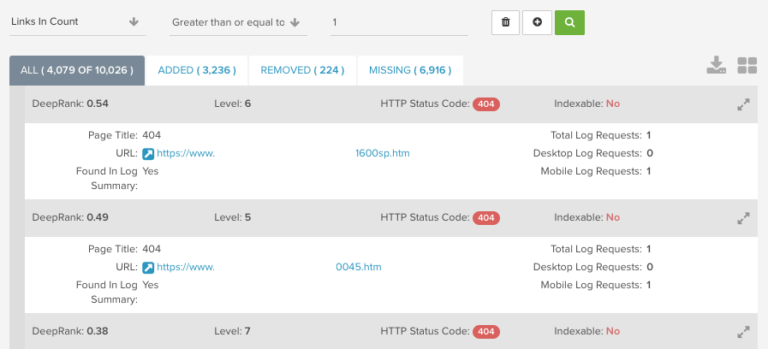
Actions
Here are some of the fixes you can implement to increase crawl efficiency through internal linking:
- Identify internal links receiving a significant amount of bot hits, and assess whether these are primary URLs.
- Update internal links to canonical URLs.
- Ensure that all internal links point to 200 status code final destination URLs, and aren’t redirecting.
- Identify important pages that are receiving low numbers of bot hits, and add more internal links to these pages to improve crawl frequency.
4. Site Category
Not all site categories carry the same weight and importance for a business to drive conversions through or for search engines to send organic traffic to.
For an ecommerce site, product pages will need to be crawled more frequently by search engines as they change frequently and these changes need to be continually reflected in the search engine’s index.
An evergreen blog post that is updated once a year, however, will be a much lower priority for a website in terms of crawl frequency.
Segmenting your log file data by site category can provide invaluable insights into the crawlability of each one, and how frequently they are visited by search engines.
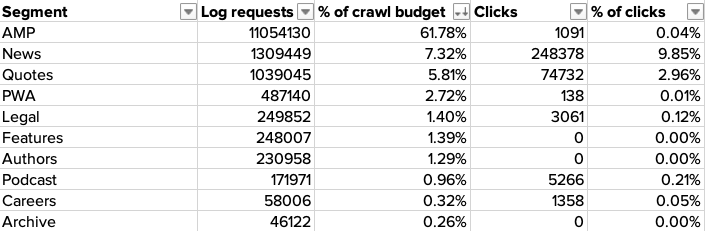
Actions
Here are some steps you can take to improve crawl efficiency across your site categories:
- Identify segments that are receiving a lot of bot hits but aren’t receiving clicks or impressions.
- Identify site segments that are receiving a low number of bot hits, and ensure they are easily accessible in the site architecture to improve crawling.
- Assess where significant crawl budget is being spread across different website variations, such as separate desktop and mobile pages and AMPs (Accelerated Mobile Pages.)
- Map crawl frequency against each segment to ensure Googlebot is able to keep up with frequently-changing page categories by crawling them regularly.
5. Organic Performance
Some of the most valuable metrics that you can overlay log file data with are organic performance metrics such as impressions in the SERPs (search engine results pages) and traffic to your website from users.
It’s important to understand how search engines crawl and navigate your website, but the end result we’re all aiming for is reaching users with our content.
A page may be getting a lot of hits from search engine bots, but this would be let down by the fact that the page isn’t getting any impressions or traffic.
Mapping performance metrics against log file data allows you to analyze how accessible your pages are for users, not just search engines.
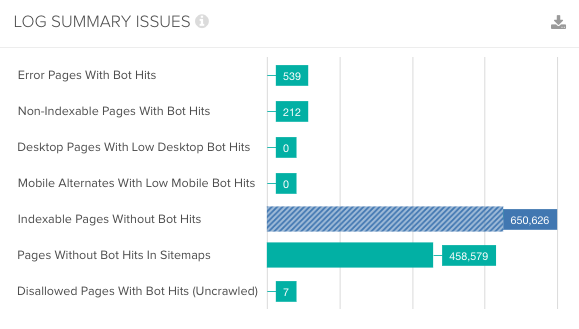
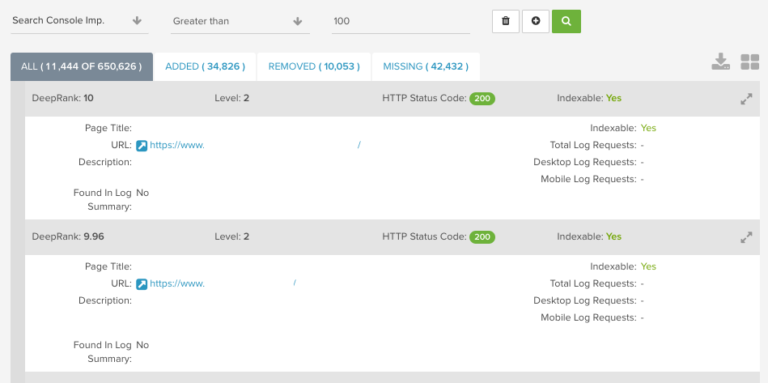
Actions
Here are some steps you can take to improve the discoverability of your key pages and their performance in organic search:
- Identify pages that are receiving traffic and impressions that are not being crawled by search engines.
- Ensure that high-performing pages are included in XML sitemaps and improve internal linking to them to encourage more regular crawling.
- Identify pages that are being crawled regularly but aren’t receiving impressions or traffic, and filter these down to primary.
- URLs to see which important pages aren’t performing as they should be in search.
- Audit these low-performing pages to check for issues that could be impacting their ranking performance, such as content quality and intent targeting, as well as indexing and rendering issues that could prevent search engines from accessing their content.
Ongoing Log File Monitoring Is Crucial
Performing a crawl budget audit using log file data in this manner is not just a one-off task. To really understand search engine behavior, it’s important to monitor these areas regularly.
Crawl behavior fluctuates on an ongoing basis, depending on a combination of factors such as Googlebot’s crawl prioritization algorithms, and technical issues on your site which can impact crawling.
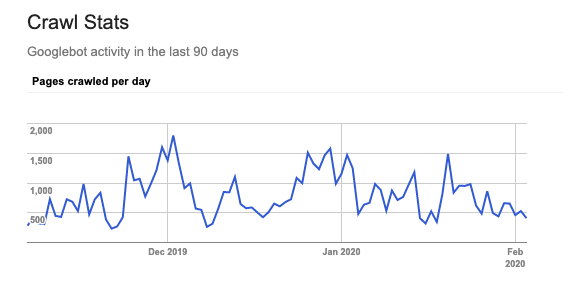
This is why it’s crucial to track changes in how crawl budget is spent across your site over time, by continually monitoring metrics such as the average bot hit rate per site segment and status code, for example.
To Sum Up
Log file analysis should play a part in every SEO professional’s day-to-day work, as log files are one of the ways where you can get closest to understanding Googlebot.
SEO tools try to mimic search engine crawler behavior, but with log files, you can analyze the real thing.
By cross-referencing search engine bot hits with important metrics like indexability, internal linking and page performance, you will be able to discover more valuable insights into the accessibility of a website for the search engines that need to crawl it.
More Resources:
Image Credits
All screenshots taken by author, February 2020