When SEO Was Easy
When I got started on the web over 15 years ago I created an overly broad & shallow website that had little chance of making money because it was utterly undifferentiated and crappy. In spite of my best (worst?) efforts while being a complete newbie, sometimes I would go to the mailbox and see a check for a couple hundred or a couple thousand dollars come in. My old roommate & I went to Coachella & when the trip was over I returned to a bunch of mail to catch up on & realized I had made way more while not working than what I spent on that trip.
What was the secret to a total newbie making decent income by accident?
Horrible spelling.
Back then search engines were not as sophisticated with their spelling correction features & I was one of 3 or 4 people in the search index that misspelled the name of an online casino the same way many searchers did.
The high minded excuse for why I did not scale that would be claiming I knew it was a temporary trick that was somehow beneath me. The more accurate reason would be thinking in part it was a lucky fluke rather than thinking in systems. If I were clever at the time I would have created the misspeller’s guide to online gambling, though I think I was just so excited to make anything from the web that I perhaps lacked the ambition & foresight to scale things back then.
In the decade that followed I had a number of other lucky breaks like that. One time one of the original internet bubble companies that managed to stay around put up a sitewide footer link targeting the concept that one of my sites made decent money from. This was just before the great recession, before Panda existed. The concept they targeted had 3 or 4 ways to describe it. 2 of them were very profitable & if they targeted either of the most profitable versions with that page the targeting would have sort of carried over to both. They would have outranked me if they targeted the correct version, but they didn’t so their mistargeting was a huge win for me.
Search Gets Complex
Search today is much more complex. In the years since those easy-n-cheesy wins, Google has rolled out many updates which aim to feature sought after destination sites while diminishing the sites which rely one “one simple trick” to rank.
Arguably the quality of the search results has improved significantly as search has become more powerful, more feature rich & has layered in more relevancy signals.
Many quality small web publishers have went away due to some combination of increased competition, algorithmic shifts & uncertainty, and reduced monetization as more ad spend was redirected toward Google & Facebook. But the impact as felt by any given publisher is not the impact as felt by the ecosystem as a whole. Many terrible websites have also went away, while some formerly obscure though higher-quality sites rose to prominence.
There was the Vince update in 2009, which boosted the rankings of many branded websites.
Then in 2011 there was Panda as an extension of Vince, which tanked the rankings of many sites that published hundreds of thousands or millions of thin content pages while boosting the rankings of trusted branded destinations.
Then there was Penguin, which was a penalty that hit many websites which had heavily manipulated or otherwise aggressive appearing link profiles. Google felt there was a lot of noise in the link graph, which was their justification for the Penguin.
There were updates which lowered the rankings of many exact match domains. And then increased ad load in the search results along with the other above ranking shifts further lowered the ability to rank keyword-driven domain names. If your domain is generically descriptive then there is a limit to how differentiated & memorable you can make it if you are targeting the core market the keywords are aligned with.
There is a reason eBay is more popular than auction.com, Google is more popular than search.com, Yahoo is more popular than portal.com & Amazon is more popular than a store.com or a shop.com. When that winner take most impact of many online markets is coupled with the move away from using classic relevancy signals the economics shift to where is makes a lot more sense to carry the heavy overhead of establishing a strong brand.
Branded and navigational search queries could be used in the relevancy algorithm stack to confirm the quality of a site & verify (or dispute) the veracity of other signals.
Historically relevant algo shortcuts become less appealing as they become less relevant to the current ecosystem & even less aligned with the future trends of the market. Add in negative incentives for pushing on a string (penalties on top of wasting the capital outlay) and a more holistic approach certainly makes sense.
Modeling Web Users & Modeling Language
PageRank was an attempt to model the random surfer.
When Google is pervasively monitoring most users across the web they can shift to directly measuring their behaviors instead of using indirect signals.
Years ago Bill Slawski wrote about the long click in which he opened by quoting Steven Levy’s In the Plex: How Google Thinks, Works, and Shapes our Lives
“On the most basic level, Google could see how satisfied users were. To paraphrase Tolstoy, happy users were all the same. The best sign of their happiness was the “Long Click” — This occurred when someone went to a search result, ideally the top one, and did not return. That meant Google has successfully fulfilled the query.”
Of course, there’s a patent for that. In Modifying search result ranking based on implicit user feedback they state:
user reactions to particular search results or search result lists may be gauged, so that results on which users often click will receive a higher ranking. The general assumption under such an approach is that searching users are often the best judges of relevance, so that if they select a particular search result, it is likely to be relevant, or at least more relevant than the presented alternatives.
If you are a known brand you are more likely to get clicked on than a random unknown entity in the same market.
And if you are something people are specifically seeking out, they are likely to stay on your website for an extended period of time.
One aspect of the subject matter described in this specification can be embodied in a computer-implemented method that includes determining a measure of relevance for a document result within a context of a search query for which the document result is returned, the determining being based on a first number in relation to a second number, the first number corresponding to longer views of the document result, and the second number corresponding to at least shorter views of the document result; and outputting the measure of relevance to a ranking engine for ranking of search results, including the document result, for a new search corresponding to the search query. The first number can include a number of the longer views of the document result, the second number can include a total number of views of the document result, and the determining can include dividing the number of longer views by the total number of views.
Attempts to manipulate such data may not work.
safeguards against spammers (users who generate fraudulent clicks in an attempt to boost certain search results) can be taken to help ensure that the user selection data is meaningful, even when very little data is available for a given (rare) query. These safeguards can include employing a user model that describes how a user should behave over time, and if a user doesn’t conform to this model, their click data can be disregarded. The safeguards can be designed to accomplish two main objectives: (1) ensure democracy in the votes (e.g., one single vote per cookie and/or IP for a given query-URL pair), and (2) entirely remove the information coming from cookies or IP addresses that do not look natural in their browsing behavior (e.g., abnormal distribution of click positions, click durations, clicks_per_minute/hour/day, etc.). Suspicious clicks can be removed, and the click signals for queries that appear to be spmed need not be used (e.g., queries for which the clicks feature a distribution of user agents, cookie ages, etc. that do not look normal).
And just like Google can make a matrix of documents & queries, they could also choose to put more weight on search accounts associated with topical expert users based on their historical click patterns.
Moreover, the weighting can be adjusted based on the determined type of the user both in terms of how click duration is translated into good clicks versus not-so-good clicks, and in terms of how much weight to give to the good clicks from a particular user group versus another user group. Some user’s implicit feedback may be more valuable than other users due to the details of a user’s review process. For example, a user that almost always clicks on the highest ranked result can have his good clicks assigned lower weights than a user who more often clicks results lower in the ranking first (since the second user is likely more discriminating in his assessment of what constitutes a good result). In addition, a user can be classified based on his or her query stream. Users that issue many queries on (or related to) a given topic T (e.g., queries related to law) can be presumed to have a high degree of expertise with respect to the given topic T, and their click data can be weighted accordingly for other queries by them on (or related to) the given topic T.
Google was using click data to drive their search rankings as far back as 2009. David Naylor was perhaps the first person who publicly spotted this. Google was ranking Australian websites for [tennis court hire] in the UK & Ireland, in part because that is where most of the click signal came from. That phrase was most widely searched for in Australia. In the years since Google has done a better job of geographically isolating clicks to prevent things like the problem David Naylor noticed, where almost all search results in one geographic region came from a different country.
Whenever SEOs mention using click data to search engineers, the search engineers quickly respond about how they might consider any signal but clicks would be a noisy signal. But if a signal has noise an engineer would work around the noise by finding ways to filter the noise out or combine multiple signals. To this day Google states they are still working to filter noise from the link graph: “We continued to protect the value of authoritative and relevant links as an important ranking signal for Search.”
The site with millions of inbound links, few intentional visits & those who do visit quickly click the back button (due to a heavy ad load, poor user experience, low quality content, shallow content, outdated content, or some other bait-n-switch approach)…that’s an outlier. Preventing those sorts of sites from ranking well would be another way of protecting the value of authoritative & relevant links.
Best Practices Vary Across Time & By Market + Category
Along the way, concurrent with the above sorts of updates, Google also improved their spelling auto-correct features, auto-completed search queries for many years through a featured called Google Instant (though they later undid forced query auto-completion while retaining automated search suggestions), and then they rolled out a few other algorithms that further allowed them to model language & user behavior.
Today it would be much harder to get paid above median wages explicitly for sucking at basic spelling or scaling some other individual shortcut to the moon, like pouring millions of low quality articles into a (formerly!) trusted domain.
Nearly a decade after Panda, eHow’s rankings still haven’t recovered.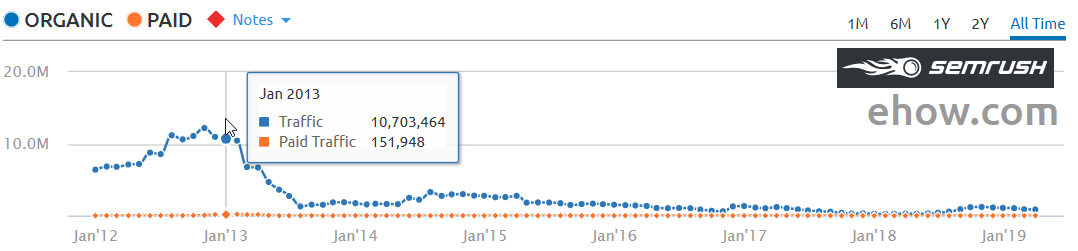
Back when I got started with SEO the phrase Indian SEO company was associated with cut-rate work where people were buying exclusively based on price. Sort of like a “I got a $500 budget for link building, but can not under any circumstance invest more than $5 in any individual link.” Part of how my wife met me was she hired a hack SEO from San Diego who outsourced all the work to India and marked the price up about 100-fold while claiming it was all done in the United States. He created reciprocal links pages that got her site penalized & it didn’t rank until after she took her reciprocal links page down.
With that sort of behavior widespread (hack US firm teaching people working in an emerging market poor practices), it likely meant many SEO “best practices” which were learned in an emerging market (particularly where the web was also underdeveloped) would be more inclined to being spammy. Considering how far ahead many Western markets were on the early Internet & how India has so many languages & how most web usage in India is based on mobile devices where it is hard for users to create links, it only makes sense that Google would want to place more weight on end user data in such a market.
If you set your computer location to India Bing’s search box lists 9 different languages to choose from.
The above is not to state anything derogatory about any emerging market, but rather that various signals are stronger in some markets than others. And competition is stronger in some markets than others.
Search engines can only rank what exists.
“In a lot of Eastern European – but not just Eastern European markets – I think it is an issue for the majority of the [bream? muffled] countries, for the Arabic-speaking world, there just isn’t enough content as compared to the percentage of the Internet population that those regions represent. I don’t have up to date data, I know that a couple years ago we looked at Arabic for example and then the disparity was enormous. so if I’m not mistaken the Arabic speaking population of the world is maybe 5 to 6%, maybe more, correct me if I am wrong. But very definitely the amount of Arabic content in our index is several orders below that. So that means we do not have enough Arabic content to give to our Arabic users even if we wanted to. And you can exploit that amazingly easily and if you create a bit of content in Arabic, whatever it looks like we’re gonna go you know we don’t have anything else to serve this and it ends up being horrible. and people will say you know this works. I keyword stuffed the hell out of this page, bought some links, and there it is number one. There is nothing else to show, so yeah you’re number one. the moment somebody actually goes out and creates high quality content that’s there for the long haul, you’ll be out and that there will be one.” – Andrey Lipattsev – Search Quality Senior Strategist at Google Ireland, on Mar 23, 2016
Impacting the Economics of Publishing
Now search engines can certainly influence the economics of various types of media. At one point some otherwise credible media outlets were pitching the Demand Media IPO narrative that Demand Media was the publisher of the future & what other media outlets will look like. Years later, after heavily squeezing on the partner network & promoting programmatic advertising that reduces CPMs by the day Google is funding partnerships with multiple news publishers like McClatchy & Gatehouse to try to revive the news dead zones even Facebook is struggling with.
“Facebook Inc. has been looking to boost its local-news offerings since a 2017 survey showed most of its users were clamoring for more. It has run into a problem: There simply isn’t enough local news in vast swaths of the country. … more than one in five newspapers have closed in the past decade and a half, leaving half the counties in the nation with just one newspaper, and 200 counties with no newspaper at all.”
As mainstream newspapers continue laying off journalists, Facebook’s news efforts are likely to continue failing unless they include direct economic incentives, as Google’s programmatic ad push broke the banner ad:
“Thanks to the convoluted machinery of Internet advertising, the advertising world went from being about content publishers and advertising context—The Times unilaterally declaring, via its ‘rate card’, that ads in the Times Style section cost $30 per thousand impressions—to the users themselves and the data that targets them—Zappo’s saying it wants to show this specific shoe ad to this specific user (or type of user), regardless of publisher context. Flipping the script from a historically publisher-controlled mediascape to an advertiser (and advertiser intermediary) controlled one was really Google’s doing. Facebook merely rode the now-cresting wave, borrowing outside media’s content via its own users’ sharing, while undermining media’s ability to monetize via Facebook’s own user-data-centric advertising machinery. Conventional media lost both distribution and monetization at once, a mortal blow.”
Google is offering news publishers audience development & business development tools.
Heavy Investment in Emerging Markets Quickly Evolves the Markets
As the web grows rapidly in India, they’ll have a thousand flowers bloom. In 5 years the competition in India & other emerging markets will be much tougher as those markets continue to grow rapidly. Media is much cheaper to produce in India than it is in the United States. Labor costs are lower & they never had the economic albatross that is the ACA adversely impact their economy. At some point the level of investment & increased competition will mean early techniques stop having as much efficacy. Chinese companies are aggressively investing in India.
“If you break India into a pyramid, the top 100 million (urban) consumers who think and behave more like Americans are well-served,” says Amit Jangir, who leads India investments at 01VC, a Chinese venture capital firm based in Shanghai. The early stage venture firm has invested in micro-lending firms FlashCash and SmartCoin based in India. The new target is the next 200 million to 600 million consumers, who do not have a go-to entertainment, payment or ecommerce platform yet— and there is gonna be a unicorn in each of these verticals, says Jangir, adding that it will be not be as easy for a player to win this market considering the diversity and low ticket sizes.
RankBrain
RankBrain appears to be based on using user clickpaths on head keywords to help bleed rankings across into related searches which are searched less frequently. A Googler didn’t state this specifically, but it is how they would be able to use models of searcher behavior to refine search results for keywords which are rarely searched for.
In a recent interview in Scientific American a Google engineer stated: “By design, search engines have learned to associate short queries with the targets of those searches by tracking pages that are visited as a result of the query, making the results returned both faster and more accurate than they otherwise would have been.”
Now a person might go out and try to search for something a bunch of times or pay other people to search for a topic and click a specific listing, but some of the related Google patents on using click data (which keep getting updated) mentioned how they can discount or turn off the signal if there is an unnatural spike of traffic on a specific keyword, or if there is an unnatural spike of traffic heading to a particular website or web page.
And, since Google is tracking the behavior of end users on their own website, anomalous behavior is easier to track than it is tracking something across the broader web where signals are more indirect. Google can take advantage of their wide distribution of Chrome & Android where users are regularly logged into Google & pervasively tracked to place more weight on users where they had credit card data, a long account history with regular normal search behavior, heavy Gmail users, etc.
Plus there is a huge gap between the cost of traffic & the ability to monetize it. You might have to pay someone a dime or a quarter to search for something & there is no guarantee it will work on a sustainable basis even if you paid hundreds or thousands of people to do it. Any of those experimental searchers will have no lasting value unless they influence rank, but even if they do influence rankings it might only last temporarily. If you bought a bunch of traffic into something genuine Google searchers didn’t like then even if it started to rank better temporarily the rankings would quickly fall back if the real end user searchers disliked the site relative to other sites which already rank.
This is part of the reason why so many SEO blogs mention brand, brand, brand. If people are specifically looking for you in volume & Google can see that thousands or millions of people specifically want to access your site then that can impact how you rank elsewhere.
Even looking at something inside the search results for a while (dwell time) or quickly skipping over it to have a deeper scroll depth can be a ranking signal. Some Google patents mention how they can use mouse pointer location on desktop or scroll data from the viewport on mobile devices as a quality signal.
Neural Matching
Last year Danny Sullivan mentioned how Google rolled out neural matching to better understand the intent behind a search query.
This is a look back at a big change in search but which continues to be important: understanding synonyms. How people search is often different from information that people write solutions about. pic.twitter.com/sBcR4tR4eT— Danny Sullivan (@dannysullivan) September 24, 2018
Last few months, Google has been using neural matching, –AI method to better connect words to concepts. Super synonyms, in a way, and impacting 30% of queries. Don’t know what “soapopera effect” is to search for it? We can better figure it out. pic.twitter.com/Qrwp5hKFNz— Danny Sullivan (@dannysullivan) September 24, 2018
The above Tweets capture what the neural matching technology intends to do. Google also stated:
we’ve now reached the point where neural networks can help us take a major leap forward from understanding words to understanding concepts. Neural embeddings, an approach developed in the field of neural networks, allow us to transform words to fuzzier representations of the underlying concepts, and then match the concepts in the query with the concepts in the document. We call this technique neural matching.
To help people understand the difference between neural matching & RankBrain, Google told SEL: “RankBrain helps Google better relate pages to concepts. Neural matching helps Google better relate words to searches.”
There are a couple research papers on neural matching.
The first one was titled A Deep Relevance Matching Model for Ad-hoc Retrieval. It mentioned using Word2vec & here are a few quotes from the research paper
- “Successful relevance matching requires proper handling of the exact matching signals, query term importance, and diverse matching requirements.”
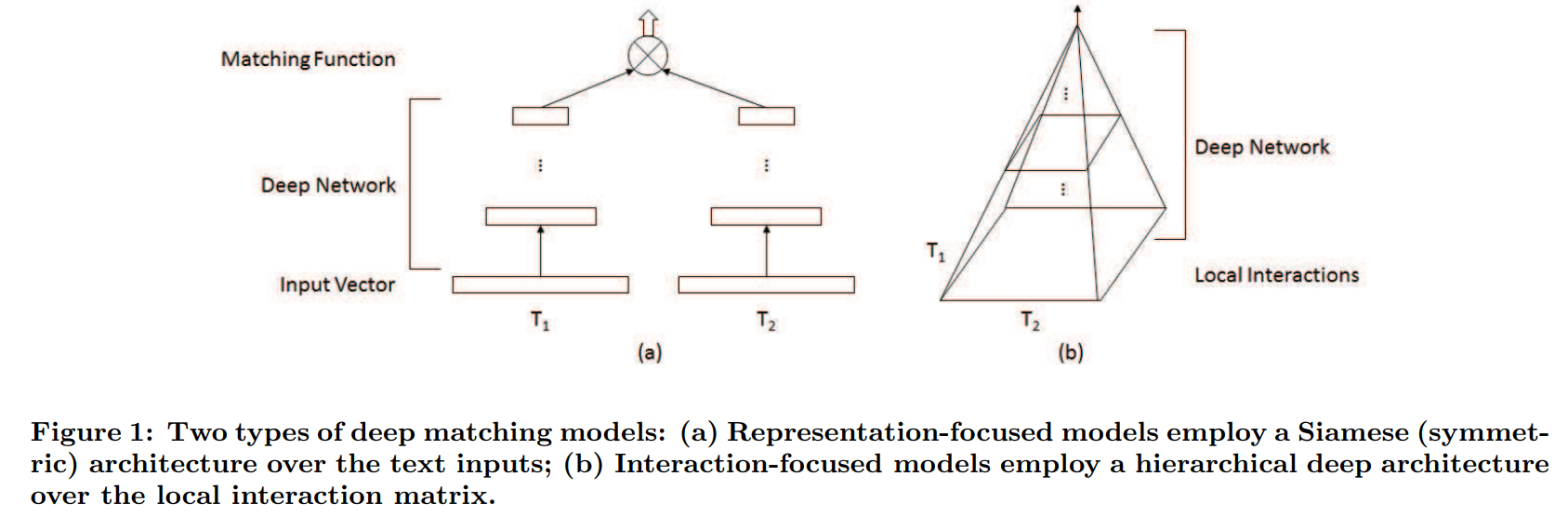
- “the interaction-focused model, which first builds local level interactions (i.e., local matching signals) between two pieces of text, and then uses deep neural networks to learn hierarchical interaction patterns for matching.”
- “according to the diverse matching requirement, relevance matching is not position related since it could happen in any position in a long document.”
- “Most NLP tasks concern semantic matching, i.e., identifying the semantic meaning and infer”ring the semantic relations between two pieces of text, while the ad-hoc retrieval task is mainly about relevance matching, i.e., identifying whether a document is relevant to a given query.”
- “Since the ad-hoc retrieval task is fundamentally a ranking problem, we employ a pairwise ranking loss such as hinge loss to train our deep relevance matching model.”
The paper mentions how semantic matching falls down when compared against relevancy matching because:
- semantic matching relies on similarity matching signals (some words or phrases with the same meaning might be semantically distant), compositional meanings (matching sentences more than meaning) & a global matching requirement (comparing things in their entirety instead of looking at the best matching part of a longer document); whereas,
- relevance matching can put significant weight on exact matching signals (weighting an exact match higher than a near match), adjust weighting on query term importance (one word might or phrase in a search query might have a far higher discrimination value & might deserve far more weight than the next) & leverage diverse matching requirements (allowing relevancy matching to happen in any part of a longer document)
Here are a couple images from the above research paper
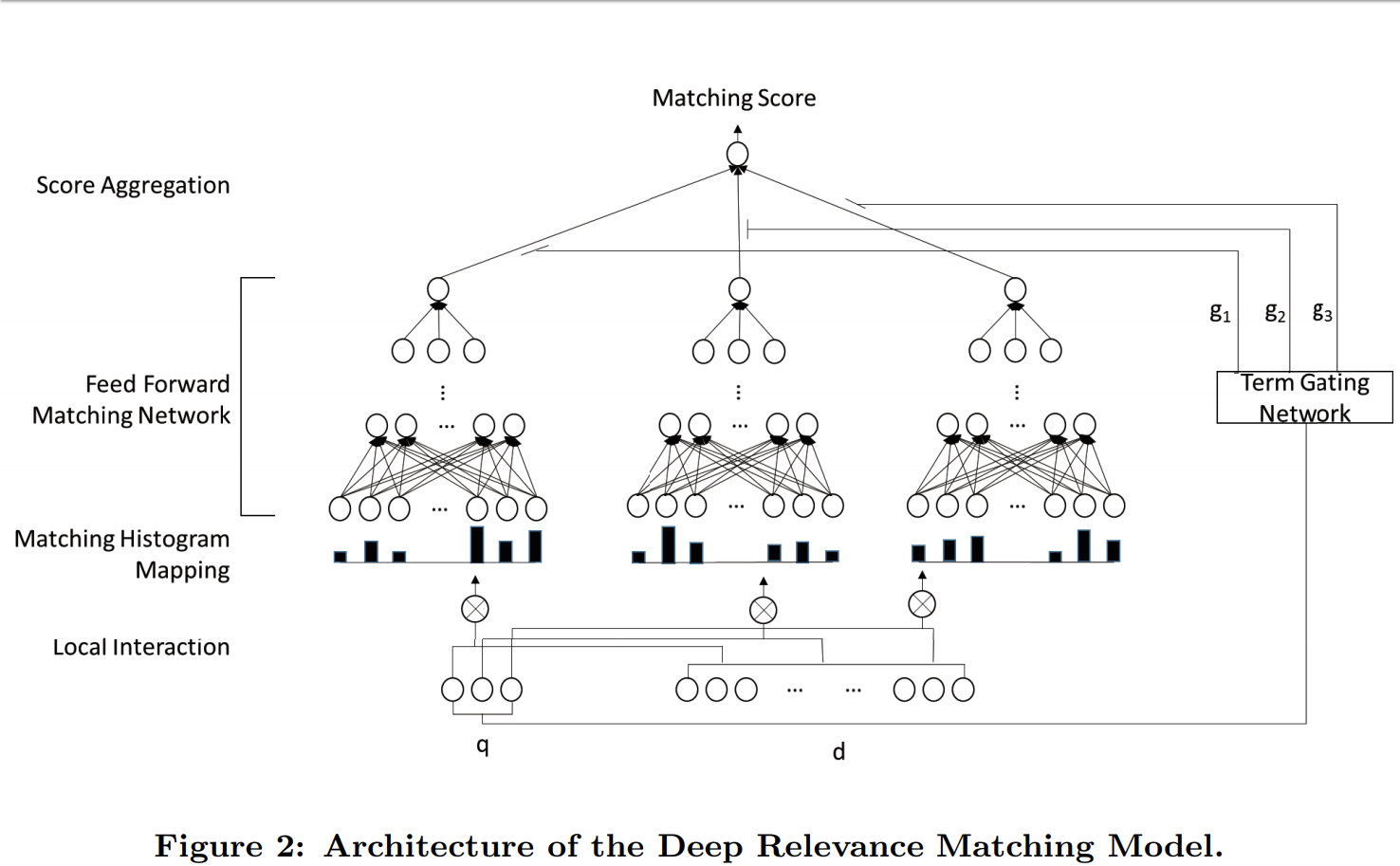
And then the second research paper is
Deep Relevancy Ranking Using Enhanced Dcoument-Query Interactions
“interaction-based models are less efficient, since one cannot index a document representation independently of the query. This is less important, though, when relevancy ranking methods rerank the top documents returned by a conventional IR engine, which is the scenario we consider here.”
That same sort of re-ranking concept is being better understood across the industry. There are ranking signals that earn some base level ranking, and then results get re-ranked based on other factors like how well a result matches the user intent.
Here are a couple images from the above research paper.
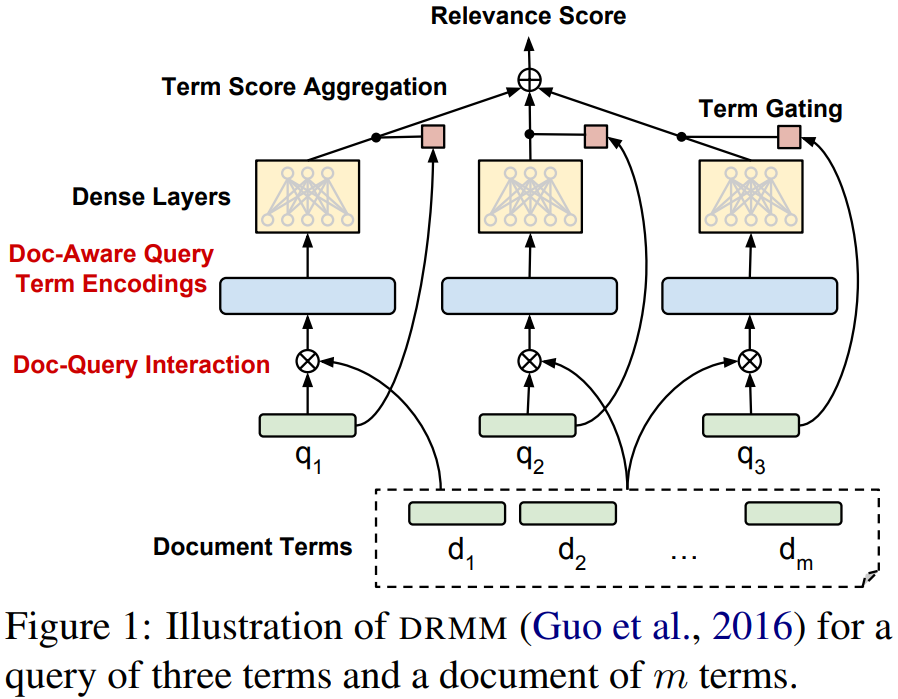
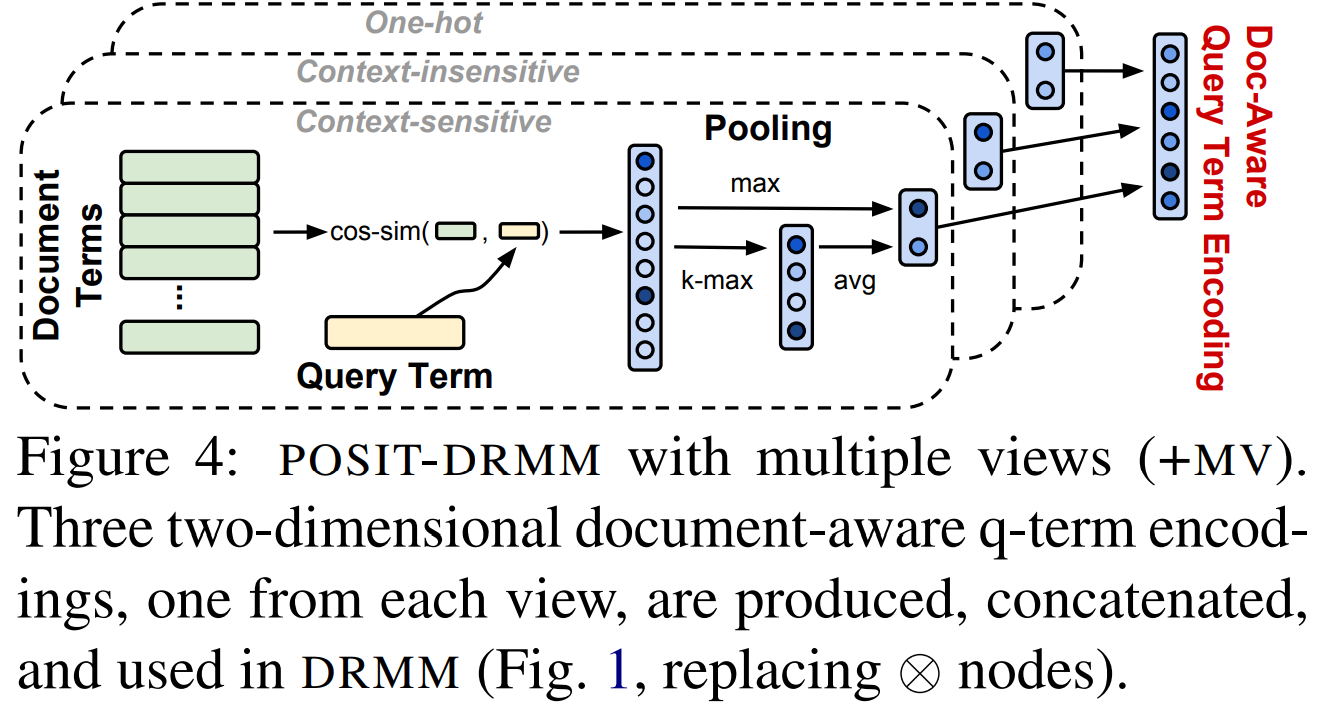
For those who hate the idea of reading research papers or patent applications, Martinibuster also wrote about the technology here. About the only part of his post I would debate is this one:
“Does this mean publishers should use more synonyms? Adding synonyms has always seemed to me to be a variation of keyword spamming. I have always considered it a naive suggestion. The purpose of Google understanding synonyms is simply to understand the context and meaning of a page. Communicating clearly and consistently is, in my opinion, more important than spamming a page with keywords and synonyms.”
I think one should always consider user experience over other factors, however a person could still use variations throughout the copy & pick up a bit more traffic without coming across as spammy. Danny Sullivan mentioned the super synonym concept was impacting 30% of search queries, so there are still a lot which may only be available to those who use a specific phrase on their page.
Martinibuster also wrote another blog post tying more research papers & patents to the above. You could probably spend a month reading all the related patents & research papers.
The above sort of language modeling & end user click feedback compliment links-based ranking signals in a way that makes it much harder to luck one’s way into any form of success by being a terrible speller or just bombing away at link manipulation without much concern toward any other aspect of the user experience or market you operate in.
Pre-penalized Shortcuts
Google was even issued a patent for predicting site quality based upon the N-grams used on the site & comparing those against the N-grams used on other established site where quality has already been scored via other methods: “The phrase model can be used to predict a site quality score for a new site; in particular, this can be done in the absence of other information. The goal is to predict a score that is comparable to the baseline site quality scores of the previously-scored sites.”
Have you considered using a PLR package to generate the shell of your site’s content? Good luck with that as some sites trying that shortcut might be pre-penalized from birth.
Navigating the Maze
When I started in SEO one of my friends had a dad who is vastly smarter than I am. He advised me that Google engineers were smarter, had more capital, had more exposure, had more data, etc etc etc … and thus SEO was ultimately going to be a malinvestment.
Back then he was at least partially wrong because influencing search was so easy.
But in the current market, 16 years later, we are near the infection point where he would finally be right.
At some point the shortcuts stop working & it makes sense to try a different approach.
The flip side of all the above changes is as the algorithms have become more complex they have went from being a headwind to people ignorant about SEO to being a tailwind to those who do not focus excessively on SEO in isolation.
If one is a dominant voice in a particular market, if they break industry news, if they have key exclusives, if they spot & name the industry trends, if their site becomes a must read & is what amounts to a habit … then they perhaps become viewed as an entity. Entity-related signals help them & those signals that are working against the people who might have lucked into a bit of success become a tailwind rather than a headwind.
If your work defines your industry, then any efforts to model entities, user behavior or the language of your industry are going to boost your work on a relative basis.
This requires sites to publish frequently enough to be a habit, or publish highly differentiated content which is strong enough that it is worth the wait.
Those which publish frequently without being particularly differentiated are almost guaranteed to eventually walk into a penalty of some sort. And each additional person who reads marginal, undifferentiated content (particularly if it has an ad-heavy layout) is one additional visitor that site is closer to eventually getting whacked. Success becomes self regulating. Any short-term success becomes self defeating if one has a highly opportunistic short-term focus.
Those who write content that only they could write are more likely to have sustained success.
A mistake people often make is to look at someone successful, then try to do what they are doing, assuming it will lead to similar success.This is backward.Find something you enjoy doing & are curious about.Get obsessed, & become one of the best at it.It will monetize itself.— Neil Strauss (@neilstrauss) March 30, 2019