
July 22, 2021
Robot.txt, On-page Robot Instructions & their Importance in SEO
Crawling, indexing, rendering and ranking are the 4 basic elements of SEO. This article will focus on how robot instructions can be improved to have a positive site-wide impact on SEO and help you manage what pages on your website should and should not be indexed for potentially ranking in Google, based on your business strategy.
Google will crawl and index as many pages on a website that they can. As long as the pages are not behind a login utility, Google will try to index all the pages it can find, unless you have provided specific robot instructions to prevent it. Hosting a robots.txt file with crawling instructions at the root of your domain is an older way to provide the search engine guidance about what should and should not be indexed and ranked on the site; It tells the search engine crawlers which pages, directories and files should or should not be indexed for potential ranking in Google or other search engines. Now, for most indexing, Google sees the robots.txt instructions as a recommendation, not a requirement (the main caveat here is that the new Google crawler, Duplex Bot, used for finding conversational information, still relies on the robots.txt file, as well as a setting in Search Console, if you need to block its access. (This will be discussed further in a future article.) Instead, Google has begun considering on-page robots instructions the primary resource for guidance about crawling and indexing. Instead, Google has begun considering on-page robots instructions the primary resource for guidance about crawling and indexing. On-page robots instructions are code that can be included in the tag of the page to indicate crawling indexing instructions just for that page. All web pages that you do not want Google to index must include specific on-page robot instructions that mirror or add to what might be included in the robots.txt file. This tutorial explains how to reliably block pages that are otherwise crawlable and not behind a firewall or login, from being indexed and ranked in Google.
How to Optimize Robot Instructions for SEO
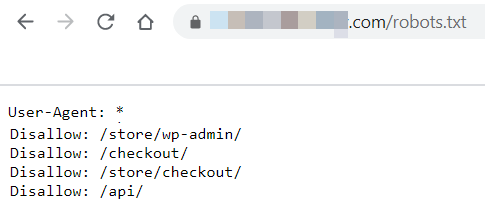
- Review your current robots.txt: You can find the robots.txt file at the root of the domain, for example: https://www.example.com/robots.txt. We should always start with making sure no SEO optimized directories are blocked in the robots.txt. Below you can see an example of a robots.txt file. In this robots.txt file, we know it is addressing all crawlers, because it says User-Agent: *. You might see robots.txt that are user agent specific, but using a star (*) is a ‘wildcard’ symbol that the rule can be applied broadly to ‘all’ or ‘any’ – in this case bots or user agents. After that, we see a list of directories after the word ‘Disallow:’. These are the directories we are requesting not to be indexed, we want to disallow bots from crawling & indexing them. Any files that appear in these directories may not be indexed or ranked.

- Review On-Page Robots Instructions: Google now takes on-page robots instructions as more of a rule than a suggestion. On-page robots instructions only effect the page that they are on and have the potential to limit crawling of the pages that are linked to from the page as well. They can be found in the source code of the page in the tag. Here is an example for on page instructions name=’robots‘ content=’index, follow‘ /> In this example, we are telling the search engine to index the page and follow the links included on the page, so that it can find other pages. To conduct an on-page instructions evaluation at scale, webmasters need to crawl their website twice: Once as the Google Smartphone Crawler or with a mobile user agent, and once as Googlebot (for desktop) or with a desktop user agent. You can use any of the cloud based or locally hosted crawlers (EX: ScreamingFrog, SiteBulb, DeepCrawl, Ryte, OnCrawl, etc.). The user-agent settings are part of the crawl settings or sometimes part of the Advanced Settings in some crawlers. In Screaming Frog, simply use the Configuration drop-down in the main nav, and click on ‘User-Agent’ to see the modal below. Both mobile and desktop crawlers are highlighted below. You can only choose one at a time, so you will crawl once with each User Agent (aka: once as a mobile crawler and once as a desktop crawler).

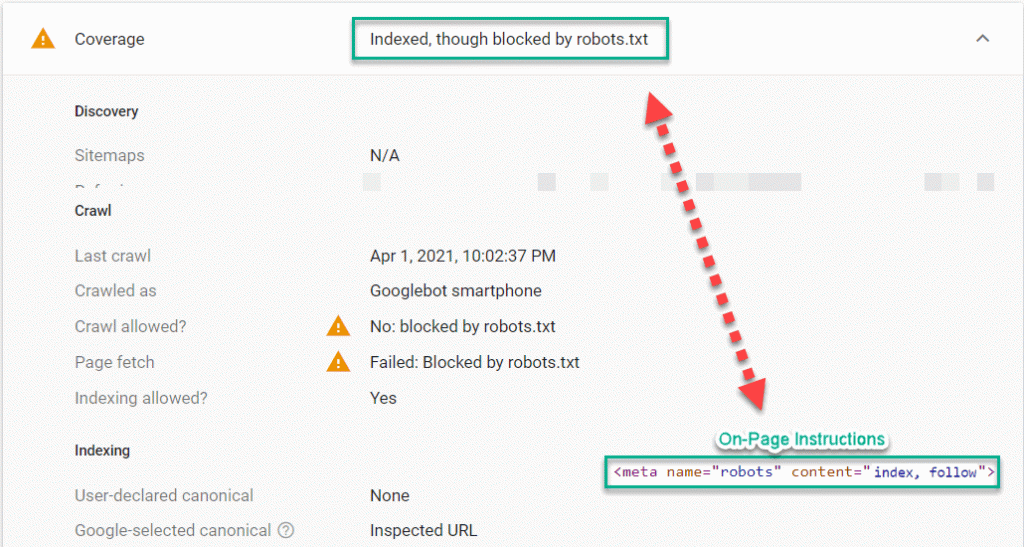
- Audit for blocked pages: Review the results from the crawls to confirm that there are no pages containing ’noindex’ instructions that should be indexed and ranking in Google. Then, do the opposite and check that all of the pages that can be indexed and ranking in Google are either marked with ‘index,follow’ or nothing at all. Make sure that all the pages that you allow Google to index would be a valuable landing page for a user according to your business strategy. If you have a high-number of low-value pages that are available to index, it could bring down the overall ranking potential of the entire site. And finally, make sure that you are not blocking any pages in the Robots.txt that you allow to be crawled by including ‘index,follow’ or nothing at all on the page. In case of mixing signals between Robots.txt and on-page robots instructions, we tend to see problems like the example below. We tested a page in Google Search Console Inspection Tool and found that a page is ‘indexed, though blocked by robots.txt’ because the on-page instructions are conflicting with the robots.txt and the on-page instructions take priority.

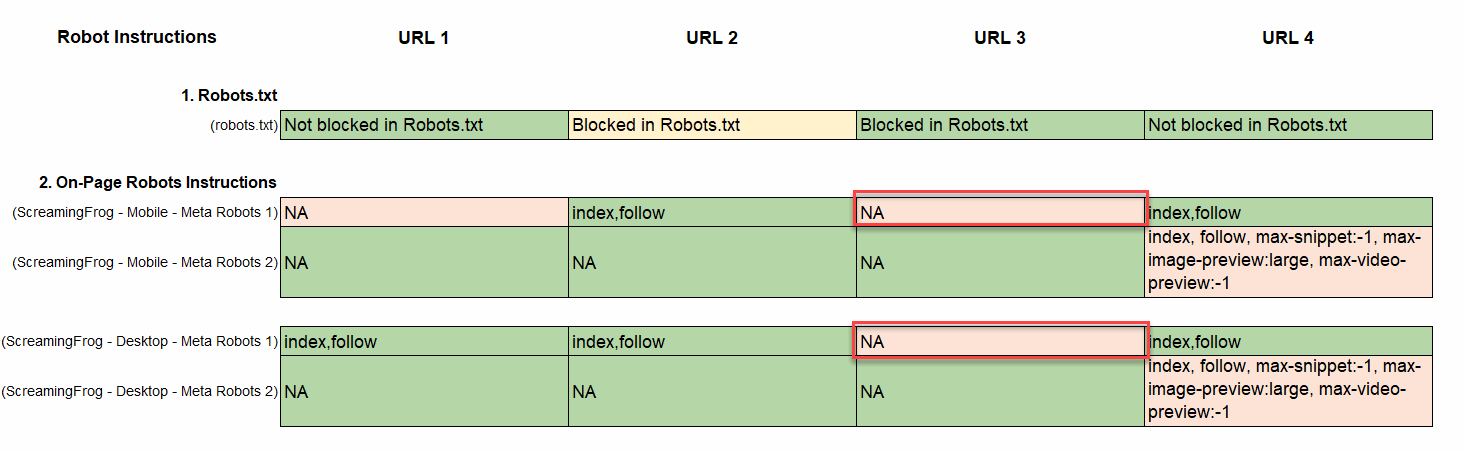
- Compare Mobile vs Desktop On-Page Instructions: Compare the crawls to confirm the on-page robots instructions match between mobile and desktop:
- If you are using Responsive Design this should not be a problem, unless elements of the Head Tag are being dynamically populated with JavaScript or Tag Manager. Sometimes that can introduce differences between the desktop and mobile renderings of the page.
- If your CMS creates two different versions of the page for the mobile and desktop rendering, in what is sometimes called ‘Adaptive Design’, ‘Adaptive-Responsive’ or ‘Selective Serving’, it is important to make sure the on-page robot instructions that are generated by the system match between mobile and desktop.
- If the tag is ever modified or injected by JavaScript, you need to make sure the JavaScript is not rewriting/removing the instruction on one or the other version(s) of the page.
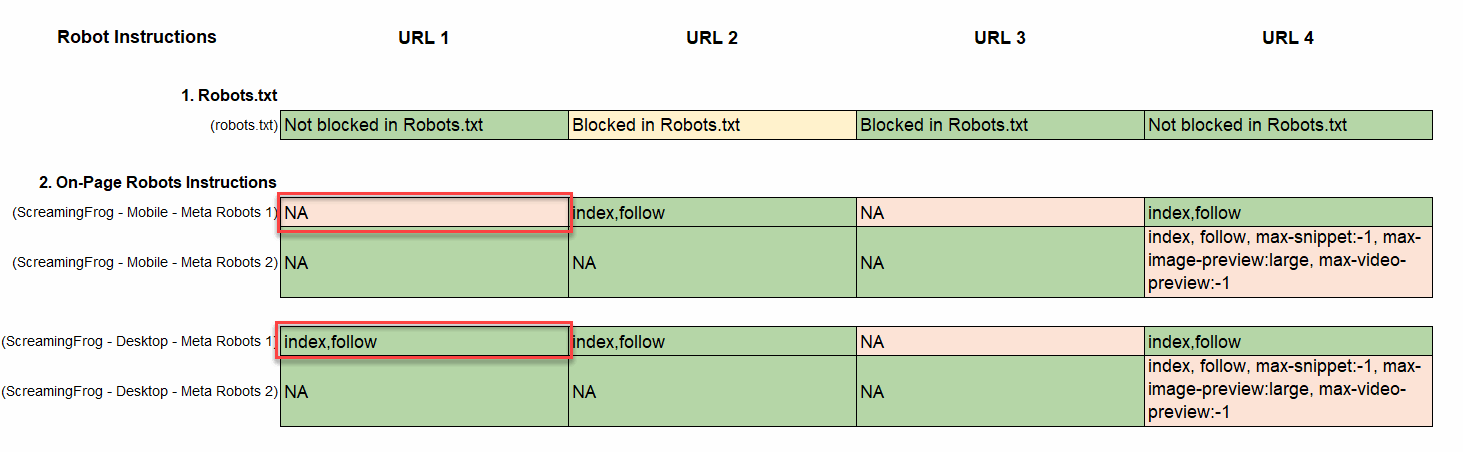
- In the example below, you can see that the Robots on-page instructions are missing on mobile but are present on desktop.

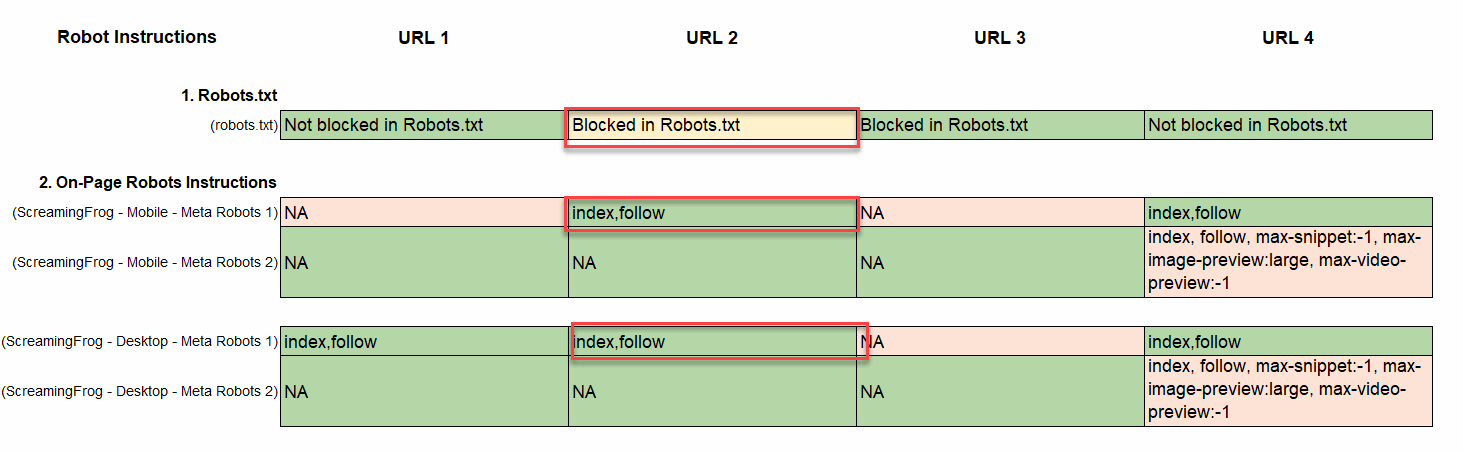
- Compare Robots.txt and Robot On-Page Instruction: Note that if the robots.txt and on-page robot instructions do not match, then the on-page robot instructions take priority and Google will probably index pages in the robots.txt file; even those with ‘Disallow: /example-page/’ if they contain on the page. In the example, you can see that the page is blocked by Robot.txt but it contains index on-page instructions. This is an example of why many webmasters see “Indexed, though blocked my Robots.txt in Google Search Console.
- Identify Missing On-Page Robot Instruction: Crawling and indexing is the default behavior for all crawlers. In the cases when page templates do not contain any on-page meta robots instructions, Google will apply ‘index,follow’ on-page crawling and indexing instructions by default. This should not be a concern as long as you want these pages indexed. If you need to block the search engines from ranking certain pages, you would need to add a noindex rule with an on-page, ‘noindex’ tag in the head tag of the HTML, like this:, in the tag of the HTML source file. In this example, The robots.txt blockers the page from indexing but we are missing on-page instructions for both, mobile and desktop. The missing instructions would not be a concern if we want the page indexed, but in this case it is highly likely that Google will index the page even though we are blocking the page with the Robots.txt.
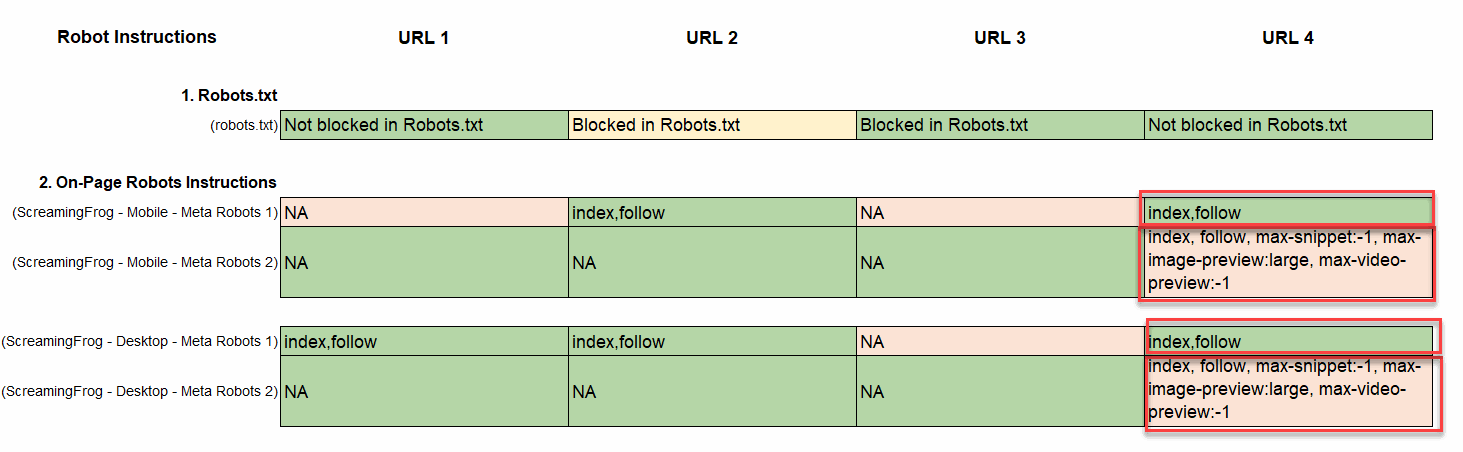
- Identify Duplicate On-Page Robot Instructions: Ideally, a page would only have one set of on-page meta robots instructions. However, we have occasionally encountered pages with multiple on-page instructions. This is a major concern because if they are not matching, then it can send confusing signals to Google. The less accurate or less optimal version of the tag should be removed. In the example below you can see that the page contains 2 sets of on-page instructions. This is a big concern when these instructions are conflicting.

Conclusion
Robots instructions are critical for SEO because they allow webmasters to manage and help with indexability of their websites. Robots.txt file and On-Page Robots Instructions (aka: robots meta tags) are two ways of telling search engine crawlers to index or ignore URLs on your website. Knowing the directives for every page of your site helps you and Google to understand the accessibility & prioritization of the content on your site. As a Best Practice, ensure that your Robots.txt file and On-Page Robots Instructions are given matching mobile and desktop directives to Google and other crawlers by auditing for mismatches regularly.
Full List of Technical SEO Articles:
- How to Discover & Manage Round Trip Requests
- How Matching Mobile vs. Desktop Page Assets can Improve Your SEO
- How to Identify Unused CSS or JavaScript on a Page
- How to Optimize Robot Instructions for Technical SEO
- How to Use Sitemaps to Help SEO