In today’s post, we get the low-down from Ali Alvi Q&A / featured snippet team lead at Bing.
Alvi’s official title is “Principal Lead Program Manager AI Products, Bing”
Read that twice and you’ll get a good idea of how much more this interview contains than “just” how to get a featured snippet.
During the podcast interview, I was looking to get an insight into how Bing generates the Q&A (featured snippet in Google-speak)…
That means I was asking how they extract the best answer to any question from the hundreds of billions of pages on the web.
I got that.
And way more.
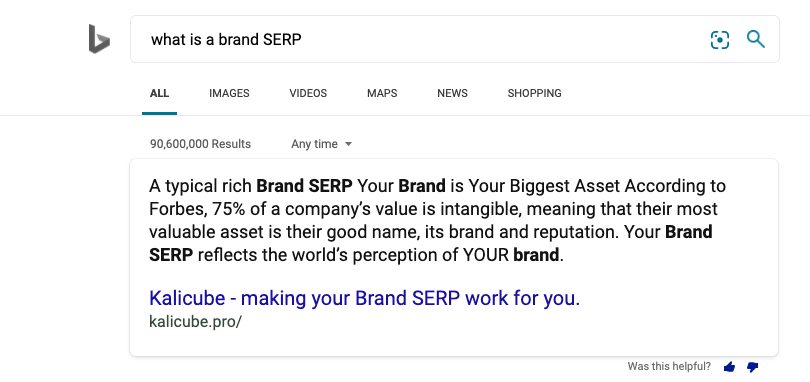
” sizes=”(max-width: 810px) 100vw, 810px” alt=”Q&A result on Bing – What is a Brand SERP?” width=”810″ height=”382″ data-srcset=”https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/what-is-a-brand-serp-qa-5e9d8c359c6a0.png 810w, https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/what-is-a-brand-serp-qa-5e9d8c359c6a0-480×226.png 480w, https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/what-is-a-brand-serp-qa-5e9d8c359c6a0-680×321.png 680w, https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/what-is-a-brand-serp-qa-5e9d8c359c6a0-768×362.png 768w” data-src=”https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/what-is-a-brand-serp-qa-5e9d8c359c6a0.png” />
Q&A / Featured Snippets
Firstly (and the raison d’etre) of this interview – I wanted to have an informative chat with someone from the team that works on the algorithm to generate the best possible answer. (Answer Engine Optimization is my thing.)
Descriptions (Snippets That Aren’t Featured)
Unexpectedly, I also got an insight into the algorithm that generates the descriptions used under the traditional blue links.
Turns out that the two are intimately linked.
Alvi (under) states that beautifully – for Q&A, Google uses the term “featured snippets.”
So those results right at the top, front and center are simply blue link snippets that are featured.
Blindingly obvious, once you fully digest the idea that the text below the blue links are not “glorified meta descriptions”, but summaries of the page adapted to address the search query.
Why Meta Descriptions Don’t Affect Ranking
Meta descriptions have no effect on rankings.
Why?
Because they moved that to a different algorithm years ago.
Possibly when they told us they no longer took them into consideration. Oh jeez.
SEO experts over-optimize meta descriptions.
Everyone else fails to provide one.
Either way, site owners are doing a bad job. 🙂
Bing and Google cannot rely on us to accurately summarise our own pages.
Now you know how Bing creates the ‘blue link descriptions’ when it doesn’t like your meta description.
Q&A / Featured Snippets Grew out of the System They Created to Generate Descriptions on the Fly
So, in short, the answer we see at the top of the results is simply taking a snippet Bing or Google pulled from our content and featuring it.
Alvi makes the point that they aren’t simply “taking a snippet and featuring it.” They do a lot more than that sometimes.
They can (and sometimes do) build summaries of the corpus of text and show that.
” sizes=”(max-width: 762px) 100vw, 762px” alt=”How the Bing Q&A / Featured Snippet Algorithm Works” width=”762″ height=”254″ data-srcset=”https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/fragmented-description-5e9dcd710bf35.png 762w, https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/fragmented-description-5e9dcd710bf35-480×160.png 480w, https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/fragmented-description-5e9dcd710bf35-680×227.png 680w” data-src=”https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/fragmented-description-5e9dcd710bf35.png” />
Extracting the Implied Question from a Document
And creating a summary of the document is part of the process by which they match the answer contained in a document to the question.
Bing’s user asks a question (in the form of a search query), then Q&A looks at the top blue link results (using Turing) and creates a summary.
That summary gives the question the document implicitly answers.
Identify the implicit question that is closest to the user’s question and, bingo, you have the “best” answer / Q&A / featured snippet.
According to Alvi, they are using high ambition AI that isn’t being used elsewhere, not even in academia. They are teaching machines how to read and understand.
Turing is key to Q&A, but much more than that…
Turing Drives Snippets, That Drive Q&A… & Every Microsoft Product
“Within Bing, we have a group of applied researchers who are working on high ambition natural language processing algorithms…” says Alvi.
The snippets team “are the hub for those algorithms for all of Microsoft.”
From what I understand that means that the team that drives these (seemingly innocuous) descriptions provides the algos to understand corpuses of text, and extract or create chunks of text for display – not only to any candidate set that needs it, but also any platform or software such as Word or Excel.
From an SEO point of view, that means the practice of using machine learning (in the form of Turing at Bing) to create the text that displays to users from titles to descriptions to summaries to answers to questions to… well, who knows?
From a wider perspective, it seems that the way this develops for descriptions of SERPs will give a window into where it is going elsewhere on the Microsoft ecosystem.
Once Alvi says it, it is blindingly obvious that there has to be heavy centralization for this type of technology (so we can use our imaginations and think up some other possible examples).
The interesting thing here is that something that covers (or will cover) all Microsoft products is being farmed out to them from the descriptions for the ten blue links.
Back to How the Search Algorithms Work
Darwinism in Search Is a Thing – 100%

” sizes=”(max-width: 681px) 100vw, 681px” alt=”Charles Darwin looking at a SERP” width=”681″ height=”415″ data-srcset=”https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/illustration-darwin-transparent-5e9daf2378f98.png 1777w, https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/illustration-darwin-transparent-5e9daf2378f98-480×292.png 480w, https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/illustration-darwin-transparent-5e9daf2378f98-680×414.png 680w, https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/illustration-darwin-transparent-5e9daf2378f98-768×468.png 768w, https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/illustration-darwin-transparent-5e9daf2378f98-1024×624.png 1024w, https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/illustration-darwin-transparent-5e9daf2378f98-1600×974.png 1600w” data-src=”https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/illustration-darwin-transparent-5e9daf2378f98.png” />
This interview is a lovely segue from the article I wrote after hearing how Google ranking works from Gary Illyes at Google.
I had asked Illyes if there is a separate algorithm for the featured snippet and he said “No”…
There is a core algorithm for the blue links and all the candidate sets use that in a modular manner, applying different weightings to the factors (or more accurately, features) in a modular fashion.
Alvi states “the idea is exactly that.”
In the first episode, Frédéric Dubut confirms this, and in the fifth Nathan Chalmers (Whole Page Team Lead) also confirms, so we are now on very safe ground: Darwinism in search is a “thing.”
The Foundation Is Always the 10 Blue Links
Alvi makes a great point: search engines evolve (ooooh, Darwinism again).
Historically, for the first 15 years or so, search engines were just 10 blue links.
Then when new features like Q&A come along, they have to fit on top of the original system without disrupting the core.
Simple.
Brilliant.
Logical.
Q&A: ‘The Best Answer From the Top Ranking Blue Links’
The Q&A algorithm is simply running through the top results from the blue links to see if it can pull content from one of the documents that accurately answer this question right on the spot.
So ranking in the top 20 or so is necessary (the exact number is unclear, and almost certainly varies on a case-by-case basis).
There is an interesting exception (see below).
Perhaps we tend to forget that people who use Bing and Google trust them.
As a user, we tend to trust the answer at the top. And that is crucial to understanding how both businesses function.
For both, their users are, in truth, their clients. Like any business, Google and Bing must serve their clients.
Those clients want and expect a simple answer to a question, or a quick solution to a problem.
Q&A / featured snippets are the simplest and quickest solution they can provide their clients.
Part of Alvi’s job is to ensure that the result Bing provides sits with the expectations of their clients, Microsoft’s corporate image, and Bing’s business model.
That is a delicate balance that all businesses face:
- Satisfy users.
- Maintain a corporate image.
- Make money.
In the case of Q&A (or, any search result for that matter), that means providing the “best, most convenient answer” for the user without being perceived as wrong, biased, misleading, offensive, or whatever.
Quirk: To Get a Q&A Place You Don’t Necessarily Have to Rank in the Blue Links
Alvi states that most of the time, Q&A simply builds on top of the blue links.
But they memorize the results they show and sometimes show a result that isn’t currently in the blue links.
So, you have to rank to get the Q&A in the first place, but you don’t need to maintain that blue link ranking to be considered for the Q&A spot in the future since Q&A has a memory.
What Are the Ranking Factors for Q&A?
Expertise, Authority & Trust. Simple.
Bing use the term “Relevancy” rather than expertise.
What they mean is accuracy, and is not a million miles away from the concept of expertise.
So Q&A is very much E-A-T-based.
Google and Bing are looking at our Expertise, Authority, and Trust because they want to show the “best” results – those that make them appear expert, authoritative and trustworthy to their users.
Now, doesn’t that make sense?
” sizes=”(max-width: 481px) 100vw, 481px” alt=”How the Bing Q&A / Featured Snippet Algorithm Works” width=”481″ height=”552″ data-srcset=”https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/fs-blue-links-5e9db325df888.png 689w, https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/fs-blue-links-5e9db325df888-480×551.png 480w, https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/fs-blue-links-5e9db325df888-680×781.png 680w” data-src=”https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/fs-blue-links-5e9db325df888.png” />
Here’s the Process to Find the ‘Best’ Answer
The algo starts with relevance.
Is the answer correct?
If so, it gets a chance.
The correctness of any document is based on whether it conforms to accepted opinion and the quality of the document.
Both of these are determined by the algorithms’ understanding of entities and their relationships (so entity-based search is a thing, too).
Once an entity is identified as key to the answer, neural networks figure out if that entity is present in this answer.
And if so, what is the context vis-a-vis other related entities also present and how closely does that mini knowledge graph correspond to the “accepted truth.”
Then, from those documents that are relevant (or accurate/correct /expert – choose your version), they will look at the authority and trust signals.
End-to-end neural networks evaluate the explicit and implicit authority and trust of the document, author, and publisher.
End-to-End Neural Networks
Alvi is insistent that Q&A is pretty much end-to-end neural networks / machine learning.
Like Dubut, he sees the algorithm as simply a measuring model…
It measures success and failure and adapts itself accordingly.
Measuring Success & Failure: User Feedback
With end-to-end neural networks, the control that humans have is the data they put in and the metrics they use to judge performance.
They feed what I would call “corrective data” to the machine on an ongoing basis.
The aim is to indicate to the machine:
- Where it is getting things right (Dubut talks about reinforcement in learning) .
- When it gets it wrong (that pushes the machine to adjust).
Much of that data is based on user feedback in the form of:
- Judges (the equivalent of quality raters at Google – Dubut talks about them here).
- Surveys.
- Feedback from the SERP.
Alvi suggests that this is key to how the machine is judged, but also how the team themselves are judged.
The relevant team members are required to respond internally.
The principal responsibility of the team behind the algo is creating a reliable algorithm that generates results that build trust in the search engine.
For me, that feeds back into the idea that people who search on Bing or Google are their clients.
Like any other business, their business model relies on satisfying those clients.
And like any other business, they have every interest in using client feedback to improve the product.
Ranking Factors Are Out, Metrics Are In
Since machine learning dominates the ranking process, the key question is not “what are the factors” but “what are the metrics.”
The actual calculation of the rankings has become pretty much end-to-end neural networks.
And what humans are tasked to do is to set the metrics, do quality control, and feed clean, labeled data to encourage the machine to correct itself.
The factors the machine uses to meet that measurement is something we (and they) cannot know.
The models Bing has in production have hundreds of millions of parameters.
There is no way anyone can actually go in and understand what is going on. The only way to measure it is give it input and measure the output.
We can give the machines a set of factors we think are relevant.
But once we let them loose on the data, they will identify factors we hadn’t thought of.
These implied / indirect factors are not known to the people at Bing or Google, so it is pointless asking them what they are.
Some of the factors they initially thought were important aren’t.
Some they thought weren’t a big deal are.
And some they hadn’t thought of are needed.
So the question to ask is “what are the metrics” because that is where the product teams have control. These are the measurements of success for the machine.
Importantly, the machine will latch onto whatever the metric is saying.
If the metric is not correct, the machine aims for the wrong targets, the corrective data (instructions) is misleading – and ultimately the machine will get everything wrong.
If the metric is correct, the whole process helps improve results in a virtuous circle, and the results improve for Bing’s clients.
And the Bing product is a success.
Filtering the Results / Guardrails
Since the team is judged on the quality of the results their algo produces and that quality is judged on the capacity of those results to improve Bing’s clients’ trust in the Bing product, they have a filtering algo to prevent “bad” results damaging the Bing brand.
That filter is itself an algorithm based on machine learning.
A filter that learns to identify and suppress anything unhelpful, offensive, or damaging to Bing’s reputation. For example:
- Hate speech.
- Adult content.
- Fake news.
- Offensive language.
The filter doesn’t change the chosen candidate, but simply suppresses the bid to the Whole Page algo.
Alvi interestingly points out that they simply exercise the prerogative to not answer a given question.
Annotations Are Key
“Fabrice and his team do some really amazing work that we actually absolutely rely on” Alvi says.
He goes on to say that they cannot build the algos to generate Q&A without Canel’s annotations.
And this series indicates that this is a common theme that applies to all the rich elements.
Specifically to Q&A, these annotations enable the algo to easily identify the relevant blocks and allow them to reach in and pull out the appropriate passage, wherever it appears in a document (Cindy Krum’s “Fraggles”).
” sizes=”(max-width: 730px) 100vw, 730px” alt=”What are Fraggles Search result” width=”730″ height=”372″ data-srcset=”https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/what-are-fraggles-5e9d8edfb6870.png 730w, https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/what-are-fraggles-5e9d8edfb6870-480×245.png 480w, https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/what-are-fraggles-5e9d8edfb6870-680×347.png 680w” data-src=”https://cdn.searchenginejournal.com/wp-content/uploads/2020/04/what-are-fraggles-5e9d8edfb6870.png” />
They are also the handles the snippets algo use to pull out the most appropriate part of the document when rewriting meta descriptions for the blue links.
That’s already quite cool. But it seems that Canel’s annotations go way further than simply identifying the blocks.
They go so far as to suggest possible relationships between different blocks within the document that vastly facilitates the task of pulling together text from multiple parts of the document and stitching them together.
So, on top of everything else it does, Bingbot has a strong semantic labeling role, too.
And that brings back once again quite how fundamental it is that we structure our pages and give Bingbot (and Googlebot) as many clues as possible so that it can add the richest possible layer of annotation to our HTML, since that annotation vastly helps the algos extract and make the best use of our (wonderful) content.
Q&A Is Leading the Way
Q&A is front and center right at the top in the results, it is a hub used by all the other Microsoft products and it is central to the task-based journey that Bing and Google are talking about as the future of search.
Q&A / featured snippets are the ones really pushing the boundaries and are at the fore and a focal point for us all: Bing, Google, their users, and us as search marketers – which inspires me to say this…
SEO Strategy in a Nutshell
As I listen back to the conversations to write this series of articles, it strikes me just how closely all this fits together.
For me, it is now crystal clear that the entire process of crawling, storing and ranking results (be they blue links or rich elements) is deeply inter-reliant.
And, given what Canel, Dubut, Alvi, Merchant, and Chalmers share in this series, our principal focuses can usefully be summarized as:
- Structuring our content to make it easy to crawl, extract and annotate.
- Making sure our content is valuable to the subset of their users that is our audience.
- Building E-A-T at content, author and publisher levels.
And that is true whatever content we are asking Bing (or Google) to present to their users – whether for blue links or rich elements.
More Resources:
Image Credits
Featured & In-Post Images: Véronique Barnard, Kalicube.pro