Were you unable to attend Transform 2022? Check out all of the summit sessions in our on-demand library now! Watch here.
The text-to-image generator revolution is in full swing with tools such as OpenAI’s DALL-E 2 and GLIDE, as well as Google’s Imagen, gaining massive popularity – even in beta – since each was introduced over the past year.
These three tools are all examples of a trend in intelligence systems: Text-to-image synthesis or a generative model extended on image captions to produce novel visual scenes.
Intelligent systems that can create images and videos have a wide range of applications, from entertainment to education, with the potential to be used as accessible solutions for those with physical disabilities. Digital graphic design tools are widely used in the creation and editing of many modern cultural and artistic works. Yet, their complexity can make them inaccessible to anyone without the necessary technical knowledge or infrastructure.
That’s why systems that can follow text-based instructions and then perform a corresponding image-editing task are game-changing when it comes to accessibility. These benefits can also be easily extended to other domains of image generation, such as gaming, animation and creating visual teaching material.
The rise of text-to-image AI generators
AI has advanced over the past decade because of three significant factors – the rise of big data, the emergence of powerful GPUs and the re-emergence of deep learning. Generator AI systems are helping the tech sector realize its vision of the future of ambient computing — the idea that people will one day be able to use computers intuitively without needing to be knowledgeable about particular systems or coding.
AI text-to-image generators are now slowly transforming from generating dreamlike images to producing realistic portraits. Some even speculate that AI art will overtake human creations. Many of today’s text-to-image generation systems focus on learning to iteratively generate images based on continual linguistic input, just as a human artist can.
This process is known as a generative neural visual, a core process for transformers, inspired by the process of gradually transforming a blank canvas into a scene. Systems trained to perform this task can leverage text-conditioned single-image generation advances.
How 3 text-to-image AI tools stand out
AI tools that mimic human-like communication and creativity have always been buzzworthy. For the past four years, big tech giants have prioritized creating tools to produce automated images.
There have been several noteworthy releases in the past few months – a few were immediate phenomenons as soon as they were released, even though they were only available to a relatively small group for testing.
Let’s examine the technology of three of the most talked-about text-to-image generators released recently – and what makes each of them stand out.
OpenAI’s DALL-E 2: Diffusion creates state-of-the-art images
Released in April, DALL-E 2 is OpenAI’s newest text-to-image generator and successor to DALL-E, a generative language model that takes sentences and creates original images.
A diffusion model is at the heart of DALL-E 2, which can instantly add and remove elements while considering shadows, reflections and textures. Current research shows that diffusion models have emerged as a promising generative modeling framework, pushing the state-of-the-art image and video generation tasks. To achieve the best results, the diffusion model in DALL-E 2 uses a guidance method for optimizing sample fidelity (for photorealism) at the price of sample diversity.
DALL-E 2 learns the relationship between images and text through “diffusion,” which begins with a pattern of random dots, gradually altering towards an image where it recognizes specific aspects of the picture. Sized at 3.5 billion parameters, DALL-E 2 is a large model but, interestingly, isn’t nearly as large as GPT-3 and is smaller than its DALL-E predecessor (which was 12 billion). Despite its size, DALL-E 2 generates resolution that is four times better than DALL-E and it’s preferred by human judges more than 70% of the time both in caption matching and photorealism.
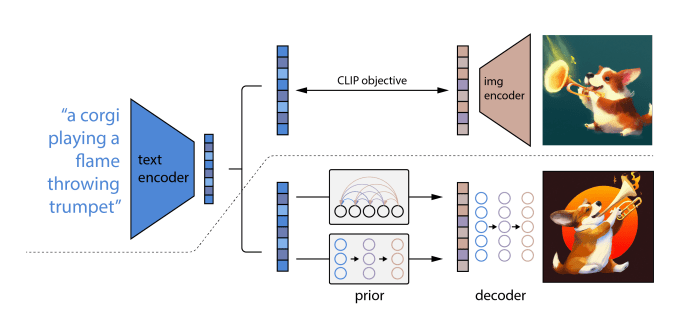
The versatile model can go beyond sentence-to-image generations and using robust embeddings from CLIP, a computer vision system by OpenAI for relating text-to-image, it can create several variations of outputs for a given input, preserving semantic information and stylistic elements. Furthermore, compared to other image representation models, CLIP embeds images and text in the same latent space, allowing language-guided image manipulations.
Although conditioning image generation on CLIP embeddings improves diversity, a specific con is that it comes with certain limitations. For example, unCLIP, which generates images by inverting the CLIP image decoder, is worse at binding attributes to objects than a corresponding GLIDE model. This is because the CLIP embedding itself does not explicitly bind characteristics to objects, and it was found that the reconstructions from the decoder often mix up attributes and objects. At the higher guidance scales used to generate photorealistic images, unCLIP yields greater diversity for comparable photorealism and caption similarity.
GLIDE by OpenAI: Realistic edits to existing images
OpenAI’s Guided Language-to-Image Diffusion for Generation and Editing, also known as GLIDE, was released in December 2021. GLIDE can automatically create photorealistic pictures from natural language prompts, allowing users to create visual material through simpler iterative refinement and fine-grained management of the created images.
This diffusion model achieves performance comparable to DALL-E, despite utilizing only one-third of the parameters (3.5 billion compared to DALL-E’s 12 billion parameters). GLIDE can also convert basic line drawings into photorealistic photos through its powerful zero-sample production and repair capabilities for complicated circumstances. In addition, GLIDE utilizes minor sampling delay and does not require CLIP reordering.
Most notably, the model can also perform image inpainting, or making realistic edits to existing images through natural language prompts. This makes it equal in function to editors such as Adobe Photoshop, but easier to use.
Modifications produced by the model match the style and lighting of the surrounding context, including convincing shadows and reflections. These models can potentially aid humans in creating compelling custom images with unprecedented speed and ease, while significantly reducing the production of effective disinformation or Deepfakes. To safeguard against these use cases while aiding future research, OpenAI’s team also released a smaller diffusion model and a noised CLIP model trained on filtered datasets.

Imagen by Google: Increased understanding of text-based inputs
Announced in June, Imagen is a text-to-image generator created by Google Research’s Brain Team. It is similar to, yet different from, DALL-E 2 and GLIDE.
Google’s Brain Team aimed to generate images with greater accuracy and fidelity by utilizing the short and descriptive sentence method. The model analyzes each sentence section as a digestible chunk of information and attempts to produce an image that is as close to that sentence as possible.
Imagen builds on the prowess of large transformer language models for syntactic understanding, while drawing the strength of diffusion models for high-fidelity image generation. In contrast to prior work that used only image-text data for model training, Google’s fundamental discovery was that text embeddings from large language models, when pretrained on text-only corpora (large and structured sets of texts), are remarkably effective for text-to-image synthesis. Furthermore, through the increased size of the language model, Imagen boosts both sample fidelity and image text alignment much more than increasing the size of the image diffusion model.

Instead of using an image-text dataset for training Imagen, the Google team simply used an “off-the-shelf” text encoder, T5, to convert input text into embeddings. The frozen T5-XXL encoder maps input text into a sequence of embeddings and a 64×64 image diffusion model, followed by two super-resolution diffusion models for generating 256×256 and 1024×1024 images. The diffusion models are conditioned on the text embedding sequence and use classifier-free guidance, relying on new sampling techniques to use large guidance weights without sample quality degradation.
Imagen achieved a state-of-the-art FID score of 7.27 on the COCO dataset without ever being trained on COCO. When assessed on DrawBench with current methods including VQ-GAN+CLIP, Latent Diffusion Models, GLIDE and DALL-E 2, Imagen was found to deliver better both in terms of sample quality and image-text alignment.
Future text-to-image opportunities and challenges
There is no doubt that quickly advancing text-to-image AI generator technology is paving the way for unprecedented opportunities for instant editing and generated creative output.
There are also many challenges ahead, ranging from questions about ethics and bias (though the creators have implemented safeguards within the models designed to restrict potentially destructive applications) to issues around copyright and ownership. The sheer amount of computational power required to train text-to-image models through massive amounts of data also restricts work to only significant and well-resourced players.
But there is also no question that each of these three text-to-image AI models stands on its own as a way for creative professionals to let their imaginations run wild.
VentureBeat’s mission is to be a digital town square for technical decision-makers to gain knowledge about transformative enterprise technology and transact. Learn more about membership.