Google will never explicitly tell us the specifics of the “more than 200 signals” their algorithm uses to rank a page.
Other than implementing what is commonly referred to as “SEO best practices,” we’re left dependent on a couple of things:
SEO & Context
When we see a ranking position change (e.g., a competitor moving above us in the SERPs, our site outranking a competitor, or a page becoming visible for a new set of keywords), we need to try and tie that back to a specific change or changes.
We need to contextualize it.
This could be as a result of:
Or it could be due to a competitor launching a set of new pages.
Whatever the reason might be, the closer we can get to pinpointing ranking movements to a specific set of changes, the more focused we can be with our SEO strategy.
SEO & Clues
If we’re talking about clues that help us understand ranking, what better place is there to start than the search results pages?
They are, after all, the clearest window we have into the types of pages that Google likes to rank for the queries we want to target.
Let’s explore how we can scale up the process of investigating these clues, specifically how Google interprets intent for a set of keywords.
Analyzing SERP intent, at scale, can help you diagnose why you’re having trouble gaining visibility for an important set of keywords and give you insight on what types of pages and content you need to create in order to rank.
While there are many ways to analyze SERP intent, particularly with the toolsets available from SEO software suites, I want to focus on custom extractions as a starting point.
What Are Custom Extractions?
There are plenty of great resources already out there around custom extractions, ranging from the more simple to the highly detailed, so I don’t want to waste too much time recovering old ground.
To summarize, custom extractions in this context are commands we give to a crawling tool to identify and extract information from a specific element on a webpage.
In this case, the webpage we want to crawl just happens to be a SERP.
The idea for this process came from a tweet I shared around using Screaming Frog to extract the related searches that Google displays for keywords.
This concept was then developed in a great article from Builtvisible, which walked through how you can use the same process to scrape results from the ‘People Also Ask’ suggestions that Google displays for certain keywords.

While these methods are both great techniques for content ideation and on-page optimization, they are slightly lacking when it comes to identifying intent.
Even if you have access to a tool that can tell you what SERP features (local pack, featured snippets etc.), are present for a keyword, I’ve found this isn’t always reliable in identifying what types of pages Google likes for the “true” organic results.
For example, we could assume the presence of a Local Pack would suggest a “Visit” intent, but the rest of the search results can often favor informational results that could be more applicable as a “Know” intent classification.
So, what gives us the best insight into how Google is interpreting keyword intent?
In my opinion, it’s contained within the page titles and meta descriptions that Google displays.
Scraping Page Titles & Meta Descriptions from Google
Let’s run through the process of scraping some data from search engine results pages.
The first thing you need to do is pull together a list of SERP URLs that you want to crawl. These are the URLs that Google would display for the query you enter.
Compiling these is straightforward. All you need to do is a simple Excel formula that follows this format (A3 being the cell containing your keyword):
="https://www.google.co.uk/search?q="&SUBSTITUTE(A3," ","+")
Or alternatively, you can make a copy of this Google Sheet with the formula already set up for you:
https://docs.google.com/spreadsheets/d/1_E_Xb8eR7ke1jFbedA4iKyNfKuzGdDn10qAZQxd55ZU/edit?usp=sharing
You can also customize these SERP URLs as much or as little as you want by appending simple search parameters to your URL.
For this exercise, you generally want to dabble with the original results as little as possible. But here are some of the more important changes you can make.
If you want to scrape more than 10 results, append this to your SERP URL:
&num=20
Change the “20” to however many results you want to crawl.
This doesn’t need to be a number divisible by 10.
You could change it to 3 if you only wanted to look at the top 3 results for a query, for example.
Or, let’s say you’re working on an international site with a presence in multiple markets. In this case, you might want to change the country of origin for your search.
This is done through this parameter:
&cr=countryXX
Change the “XX” to the country code that you want to search for.
You can find a full list of country codes here.
If you want to increase the specificity of your localized search, you can even specify a language for your search.
To do this, use this parameter:
&lr=lang_XX
Again, change the “XX” to the language code that is relevant to your research.
You can find a list of Google supported language codes here.
So you can be as specific (within reason), or as broad as you want to be.
Let’s say one of your keywords was “office space to rent” and you want to get the top 3 search results based in France with a preferred language of French. Your crawlable SERP URL would look like this:
https://www.google.co.uk/search?q=office+space+to+rent&num=3&cr=countryFR&lr=lang_fr
Or if you only wanted to look for the keyword itself, this would the URL:
https://www.google.co.uk/search?q=office+space+to+rent
With this established, we can move into the fun part: scraping the search results.
Let’s run through how to set up our custom extraction in Screaming Frog.
It’s actually very straightforward. Just follow these paths and change the relevant settings:
- Open Screaming Frog
- Change mode from Spider to List
- Configuration > Spider > Basic > Uncheck all boxes
- Configuration > Spider > Rendering > JavaScript (from the dropdown – this is generally required to scrape elements of a page that Google uses JS to inject into the SERPs)
- Configuration > Speed > Max Threads = 1 (because you don’t want Google to block your IP)
- Configuration > Speed > Limit URI/s = 1.2
Custom extraction for page titles:
- Configuration > Custom > Extraction > XPath = //div/h3 – change final dropdown to “Extract Text” and label extraction as “Page Title”
Custom extraction for meta descriptions:
- Configuration > Custom > Extraction > XPath = //ol/div/div/span – change final dropdown to “Extract Text” and label extraction as “Meta Description”

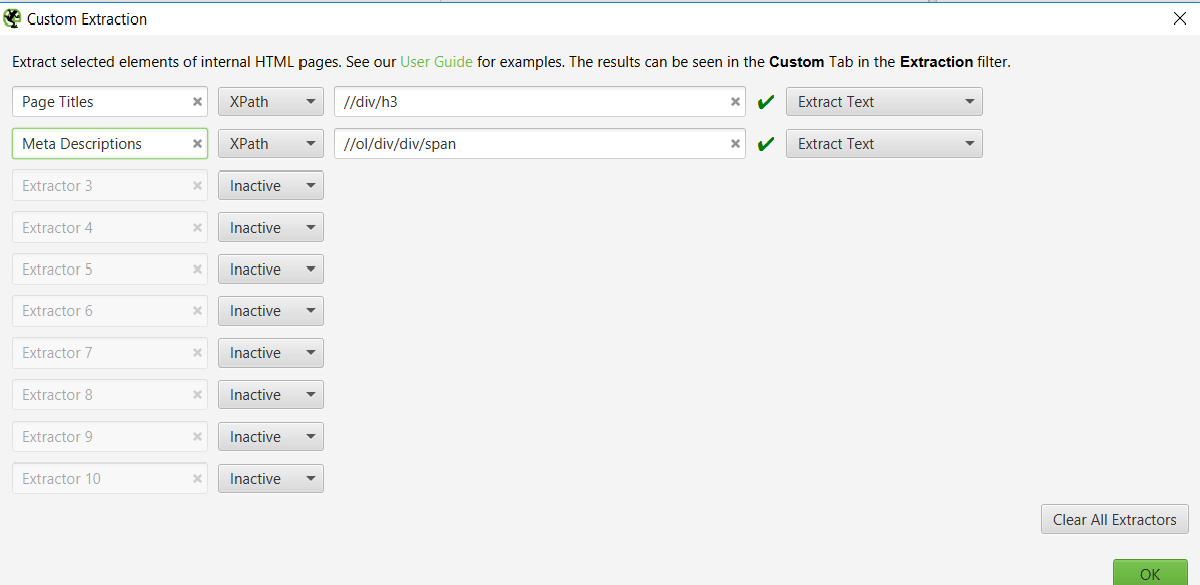
These extraction elements do not seem to change, so you should be able to continue using them without having to update the XPath you use.
When you’ve run your report, running as many SERP URLs as you need, go to the Custom tab in Screaming Frog then set the Filter dropdown to Extraction.
With a bit of luck, you should see a set of page titles and meta descriptions returned for your target keywords, matching the criteria you specified with your URL parameters.
You can now export this into Excel.
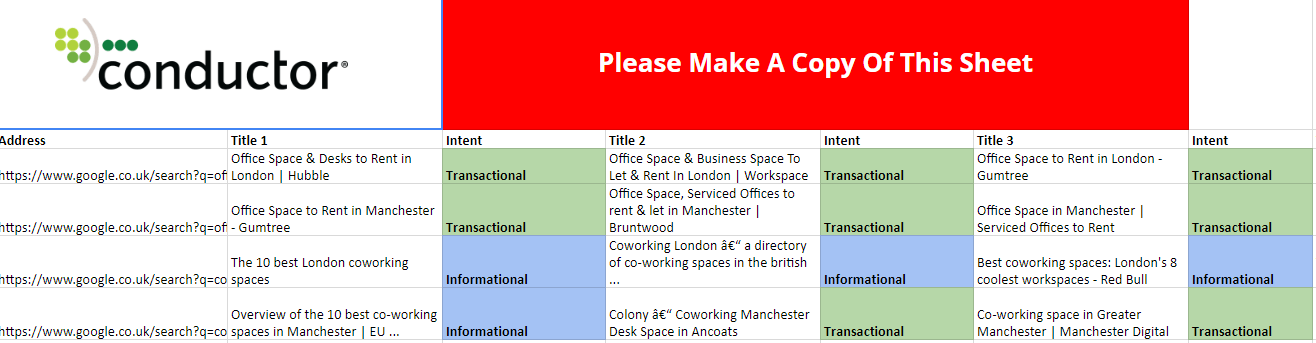
When I ran the search for four queries relating to office space and coworking space (“office space London”, “office space Manchester”, “coworking space London”, “coworking space Manchester”), this is the report I generated:

If you run the report on the same queries, you’ll notice something very interesting. Despite “office space” and “coworking space” being semantically related, Google is interpreting the intent behind variations of those queries very differently.
When I search for “office space [CITY LOCATION]”, I see page titles like this:
Office Space & Business Space To Let & Rent In London
Office Space & Desks to Rent in London
Find a London Office: Office Space London, Office Space to Rent
When I search for “coworking space [CITY LOCATION]”, I see page titles like this:
The 10 best London coworking spaces
Overview of the 10 best co-working spaces in Manchester
Best coworking spaces: London’s 8 coolest workspaces
I can see clearly that Google is seeing “office space” queries as more directly transactional, whereas it treats “coworking space” terms as more informational.
What Does This Mean for Your SEO Strategy?
It means you’re unlikely to get the same page ranking for both “office space” and “coworking space” terms, no matter how closely related the two might be.
Without analyzing the SERPs in this way, I might not have realized that Google is interpreting those keywords differently.
As AJ Kohn says: “Target the keyword, optimize the intent.”
This has been easy for me to spot as I’m only looking at four SERPs.
But what if you’re doing it for 100 keywords? Or 500? Or, dare I say it, 1,000 keywords?
There is a process that you can use to try and scale this up with a formula that you can apply to Google Sheets or Excel (whatever your weapon of choice is).
The formula looks like this:
=IF(OR(NOT(ISERR(SEARCH("how",C2))),NOT(ISERR(SEARCH("what",C2))),NOT(ISERR(SEARCH("who",C2))),NOT(ISERR(SEARCH("when",C2))),NOT(ISERR(SEARCH("why",C2))),NOT(ISERR(SEARCH("whose",C2))),NOT(ISERR(SEARCH("whether",C2))),NOT(ISERR(SEARCH("best",C2))),NOT(ISERR(SEARCH("tips",C2))))=TRUE,"Informational",IF(OR(NOT(ISERR(SEARCH("buy",C2))),NOT(ISERR(SEARCH("sale",C2))),NOT(ISERR(SEARCH("to let",C2))),NOT(ISERR(SEARCH("rent",C2))),NOT(ISERR(SEARCH("space in",C2))),NOT(ISERR(SEARCH("get",C2))))=TRUE,"Transactional","Intent not found"))
All this does is look for the presence of certain words or phrases in a page title (in the above example, contained in cell C2), and assigns an intent classification.
For the purpose of this article, I’ve only created two intent types – informational and transactional – but you can use the structure of the formula to create as many as you need.
Then you add the words you want that act as a signifier for a certain intent classification. In this example, I’ve added the following words that suggest an informational intent:
- How
- What
- Who
- When
- Whose
- Whether
- Best
And the following words that suggest a more transactional intent:
- Buy
- Sale
- To let
- Rent
- Space in
- Get
You can tweak this list as you might need to make it more relevant to the niche you’re researching, for example, I’ve included things like “rent”, “to let”, and “space in” that are more present in transactional pages.
I also find that if you can tweak your formula to classify intent accurately for 10 SERPs, you can roll this out to a bigger list and it will be accurate.
In the end, what you should end up with is a sheet that looks something like this:
https://docs.google.com/spreadsheets/d/1Scpg2v7GEP8-rrXRIfR7kQgaf7bX6a9xk2y10YEqm0s/edit?usp=sharing
The first tab shows how the intent classification works.
The second tab shows the most common intent type Google favors for the keywords you are targeting.
You can apply the same methodology to the meta descriptions Google shows to reinforce your findings, though you might want to tweak the formula above slightly.
For example, the presence of a date in a meta description often suggests the page listed is an article – this hints at informational intent.
The big takeaway: You can use this research methodology to better match the types of content you are creating to the intent that Google seems to be most commonly favoring for your target queries.
Intent Matters Now More Than Ever
It seems that these days, it doesn’t matter how many links or how much authority a page or domain has; unless you’re creating content that is optimized for intent, you’re going to face an uphill struggle to achieve the rankings you want.
Beyond that, if your page isn’t matched to intent, it’s unlikely that traffic will perform well once it arrives on the site from an engagement or conversion perspective (after all, we have to assume there’s a reason Google prefers certain intent types for specific keywords).
There’s a lot more you can do with custom extractions, especially custom SERP extractions, that can help with your SEO strategy (think data mining, outreach list building, competitor intelligence), so I hope this article is useful and can act as a framework for your own SERP extraction experiments.
Remember, it’s all about digging out those important clues that can give context to your organic strategy. Good luck and happy hunting, my fellow SEO detectives!
More SEO Resources:
Image Credits
All screenshots taken by author, August 2018
Subscribe to SEJ
Get our daily newsletter from SEJ’s Founder Loren Baker about the latest news in the industry!
